On the racetrack of building ML applications, traditional software development steps are often overtaken. Welcome to the world of MLOps, where unique challenges meet innovative solutions and consistency is king.
At Bazaarvoice, training pipelines serve as the backbone of our MLOps strategy. They underpin the reproducibility of our model builds. A glaring gap existed, however, in graduating experimental code to production.
Rather than continuing down piecemeal approaches, which often centered heavily on Jupyter notebooks, we determined a standard was needed to empower practitioners to experiment and ship machine learning models extremely fast while following our best practices.
When deciding to “buy” (it is open source after all), selecting Flyte as our workflow management platform emerged as a clear choice. It saved invaluable development time and nudged our team closer to delivering a robust self-service infrastructure. Such an infrastructure allows our engineers to build, evaluate, register, and deploy models seamlessly. Rather than reinventing the wheel, Flyte equipped us with an efficient wheel to race ahead.
Before leaping with Flyte, we embarked on an extensive evaluation journey. Choosing the right workflow orchestration system wasn’t just about selecting a tool but also finding a platform to complement our vision and align with our strategic objectives. We knew the significance of this decision and wanted to ensure we had all the bases covered. Ultimately the final tooling options for consideration were Flyte, Metaflow, Kubeflow Pipelines, and Prefect.
To make an informed choice, we laid down a set of criteria:
Criteria for Evaluation
Must-Haves:
Ease of Development: The tool should intuitively aid developers without steep learning curves.
Deployment: Quick and hassle-free deployment mechanisms.
Pipeline Customization: Flexibility to adjust pipelines as distinct project requirements arise.
Visibility: Clear insights into processes for better debugging and understanding.
Good-to-Haves:
AWS Integration: Seamless integration capabilities with AWS services.
Metadata Retention: Efficient storage and retrieval of metadata.
Startup Time: Speedy initialization to reduce latency.
Caching: Optimal data caching for faster results.
Neutral, Yet Noteworthy:
Security: Robust security measures ensuring data protection.
UserAdministration: Features facilitating user management and access control.
Cost: Affordability – offering a good balance between features and price.
Why Flyte Stood Out: Addressing Key Criteria
Diving deeper into our selection process, Flyte consistently addressed our top criteria, often surpassing the capabilities of other tools under consideration:
Ease of Development: Pure Python | Task Decorators
Python-native development experience
Pipeline Customization
Easily customize any workflow and task by modifying the task decorator
Deployment: Kubernetes Cluster
Visibility
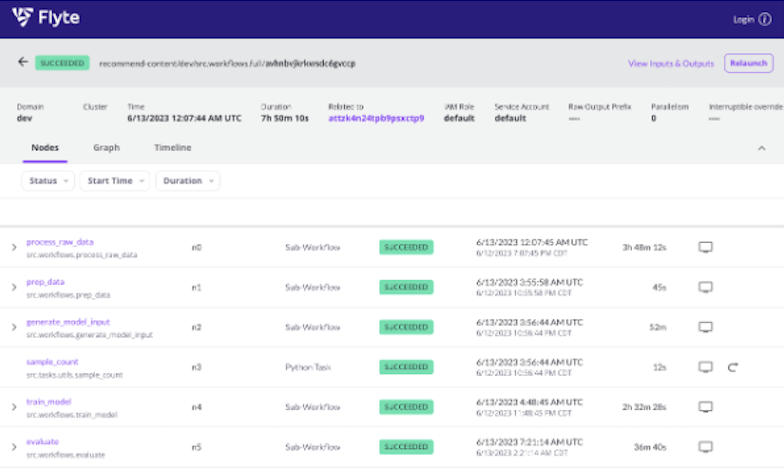
Easily accessible container logs
Flyte decks enable reporting visualizations
Flyte’s native Kubernetes integration simplified the deployment process.
The Bazaarvoice customization
As with any platform, while Flyte brought many advantages, we needed a different plug-and-play solution for our unique needs. We anticipated the platform’s novelty within our organization. We wanted to reduce the learning curve as much as possible and allow our developers to transition smoothly without being overwhelmed.
To smooth the transition and expedite the development process, we’ve developed a cookiecutter template to serve as a launchpad for developers, providing a structured starting point that’s standardized and aligned with best practices for Flyte projects. This structure empowers developers to swiftly construct training pipelines.
The most relevant files provided by the template are:
Pipfile - Details project dependencies
Dockerfile - Builds docker container
Makefile - Helper file to build, register, and execute projects
process_raw_data - workflow to extract, clean, and transform raw data
generate_model_input - workflow to create train, test, and validation data sets
train_model - workflow to generate a serialized, trained machine learning model
generate_model_output - workflow to prevent train-serving skew by performing inference on the validation data set using the trained machine learning model
evaluate - workflow to evaluate the model on a desired set of performance metrics
reporting - workflow to summarize and visualize model performance
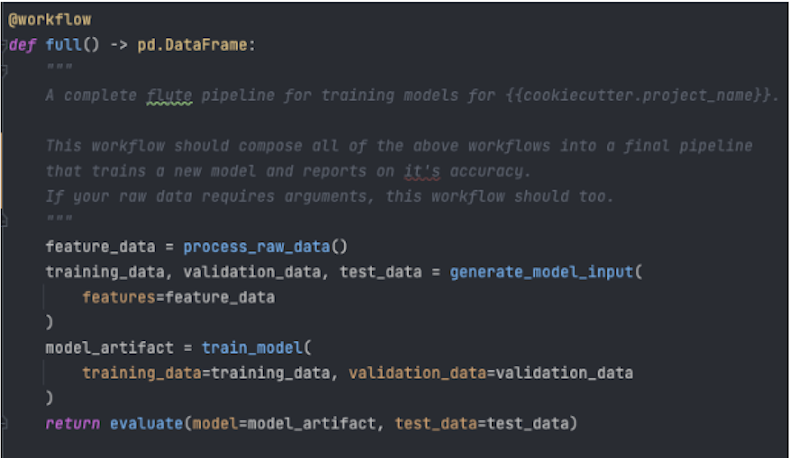
full - complete Flyte pipeline to generate trained model
tests/ - Unit tests for your workflows and tasks
run - Simplifies running of workflows
In addition, a common challenge in developing pipelines is needing resources beyond what our local machines offer. Or, there might be tasks that require extended runtimes. Flyte does grant the capability to develop locally and run remotely. However, this involves a series of steps:
Rebuild your custom docker image after each code modification.
Assign a version tag to this new docker image and push it to ECR.
Register this fresh workflow version with Flyte, updating the docker image.
Instruct Flyte to execute that specific version of the workflow, parameterizing via the CLI.
To circumvent these challenges and expedite the development process, we designed the template’s Makefile and run script to abstract the series of steps above into a single command!
./run —remote src/workflows.py full
The Makefile uses a couple helper targets, but overall provides the following commands:
info - Prints info about this project
init - Sets up project in flyte and creates an ECR repo
build - Builds the docker image
push - Pushes the docker image to ECR
package - Creates the flyte package
register - Registers version with flyte
runcmd - Generates run command for both local and remote
test - Runs any tests for the code
code_style - Applies black formatting & flake8
Key Triumphs
With Flyte as an integral component of our machine learning platform, we’ve achieved unmatched momentum in ML development. It enables swift experimentation and deployment of our models, ensuring we always adhere to best practices. Beyond aligning with fundamental MLOps principles, our customizations ensure Flyte perfectly meets our specific needs, guaranteeing the consistency and reliability of our ML models.
Closing Thoughts
Just as racers feel exhilaration crossing the finish line, our team feels an immense sense of achievement seeing our machine learning endeavors zoom with Flyte. As we gaze ahead, we’re optimistic, ready to embrace the new challenges and milestones that await. 🏎️
If you are drawn to this type of work, check out our job openings.
We build AI software in two modes: experimentation and productization. During experimentation, we are trying to see if modern technology will solve our problem. If it does, we move on to productization and build reliable data pipelines at scale.
This presents a cyclical dependency when it comes to data engineering. We need reliable and maintainable data engineering pipelines during experimentation, but don’t know what that pipeline should do until after we’ve completed the experiments. In the past, I and many data scientists I know have used an ad-hoc combination of bash scripts and Jupyter Notebooks to wrangle experimental data. While this may have been the fastest way to get experimental results and model building, it’s really a technical debt that has to be paid down the road.
The Problem
Specifically, the ad-hoc approach to experimental data pipelines causes pain points around:
Reproducibility: Ad-hoc experimentation structures puts you at risk of making results that others can’t reproduce, which can lead to product downtime if or when you need to update your approach. Simple mistakes like executing a notebook cell twice or forgetting to seed a random number generator can usually be caught. But other, more insidious problems can occur, such as behavior changes between dependency versions.
Readability: If you’ve ever come across another person’s experimental code, you know it’s hard to find where to start. Even documented projects might just say “run x script, y notebook, etc”, and it’s often unclear where the data come from and if you’re on the right track. Similarly, code reviews for data science projects are often hard to read: it’s asking a lot for a reader to differentiate between notebook code for data manipulation and code for visualization.
Maintainability: It’s common during data science projects to do some exploratory analysis or generate early results, and then revise how your data is processed or gathered. This becomes difficult and tedious when all of these steps are an unstructured collection of notebooks or scripts. In other words, the pipeline is hard to maintain: updating or changing it requires you to keep track of the whole thing.
Shareability: Ad-hoc collections of notebooks and bash scripts are also difficult for a team to work on concurrently. Each member has to ensure their notebooks are up to date (version control on notebooks is less than ideal), and that they have the correct copy of any intermediate data.
Enter Kedro
A lot of the issues above aren’t new to the software engineering discipline and have been largely solved in that space. This is where Kedro comes in. Kedro is a framework for building data engineering pipelines whose structure forces you to follow good software engineering practices. By using Kedro in the experimentation phase of projects, we build maintainable and reproducible data pipelines that produce consistent experimental results.
Specifically, Kedro has you organize your data engineering code into one or more pipelines. Each pipeline consists of a number of nodes: a functional unit that takes some data sets and parameters as inputs and produces new data sets, models, or artifacts.
This simple but strict project structure is augmented by their data catalog: a YAML file that specifies how and where the input and output data sets are to be persisted. The data sets can be stored either locally or in a cloud data storage service such as S3.
I started using Kedro about six months ago, and since then have leveraged it for different experimental data pipelines. Some of these pipelines were for building models that eventually were deployed to production, and some were collaborations with team members. Below, I’ll discuss the good and bad things I’ve found with Kedro and how it helped us create reproducible, maintainable data pipelines.
The Good
Reproducibility: I can’t say enough good things here: they nailed it. Their dependency management took a bit of getting used to but it forces a specific version on all dependencies, which is awesome. Also, the ability to just type kedro install and kedro run to execute the whole pipeline is fantastic. You still have to remember to seed random number generators, but even that is easy to remember if you put it in their params.yml file.
Function Isolation: Kedro’s fixed project structure encourages you to think about what logical steps are necessary for your pipeline, and write a single node for each step. As a result, each node tends to be short (in terms of lines of code) and specific (in terms of logic). This makes each node easy to write, test, and read later on.
Developer Parallelization: The small nodes also make it easier for developers to work together concurrently. It’s easy to spot nodes that won’t depend on each other, and they can be coded concurrently by different people.
Intermediate Data: Perhaps my favorite thing about Kedro is the data catalog. Just add the name of an output data set to catalog.yml and BOOM, it’ll be serialized to disk or your cloud data store. This makes it super easy to build up the pipeline: you work on one node, commit it, execute it, and save the results. It also comes in handy when working on a team. I can run an expensive node on a big GPU machine and save the results to S3, and another team member can simply start from there. It’s all baked in.
Code Re-usability: I’ll admit I have never re-used a notebook. At best I pulled up an old one to remind myself how I achieved some complex analysis, but even then I had to remember the intricacies of the data. The isolation of nodes, however, makes it easy to re-use them. Also, Kedro’s support for modular pipelines (i.e., packaging a pipeline into a pip package) makes it simple to share common code. We’ve created modular pipelines for common tasks such as image processing.
The Bad
While Kedro has solved many of the quality challenges in experimental data pipelines, we have noticed a few gotchas that required less than elegant work arounds:
Incremental Dataset: This support exists for reading data, but it’s lacking for writing datasets. This affected us a few times when we had a node that would take 8-10 hours to run. We lost work if the node failed part of the way through. Similarly, if the result data set didn’t fit in memory, there wasn’t a good way to save incremental results since the writer in Kedro assumes all partitions are in memory. This GitHub issue may fix it if the developers address it, but for now you have to manage partial results on your own.
Pipeline Growth: Pipelines can quickly get hard to follow since the input and outputs are just named variables that may or may not exist in the data catalog. Kedro Viz helps with this, but it’s a bit annoying to switch between the navigator and code. We’ve also started enforcing name consistency between the node names and their functions, as well as the data set names in the pipeline and the argument names in the node functions. Finally, making more, smaller pipelines is also a good way to keep your sanity. While all of these techniques help you to mentally keep track, it’s still the trade off you make for coding the pipelines by naming the inputs and outputs.
Visualization: This isn’t really considered much in Kedro, and is the one thing I’d say notebooks still have a leg up on. Kedro makes it easy for you to load the Kedro context in a notebook, however, so you can still fire one up to do some visualization. Ultimately, though, I’d love to see better support within Kedro for producing a graphical report that gets persisted to the 08_reporting layer. Right now we worked around this by making a node that renders a notebook to disk, but it’s a hack at best. I’d love better support for generating final, highly visual reports that can be versioned in the data catalog much like the intermediate data.
Conclusion
So am I a Kedro convert? Yah, you betcha. It replaces the spider-web of bash scripts and Python notebooks I used to use for my experimental data pipelines and model training, and enables better collaboration among our teams. It won’t replace a fully productionalized stream-based data pipeline for me, but it absolutely makes sure my experimental pipelines are maintainable, reproducible, and shareable.
One of the reasons why Hadoop jobs are hard to operate is their inability to provide clear, actionable error diagnostic messages for users. This stems from the fact that Hadoop consists of many interrelated components. When a component fails or behaves poorly, the failure will be cascaded to its dependent components which causes a job to fail.
This blog post is an attempt to help to solve that problem by created a user-friendly, self-serving and actionable Hadoop diagnostic system.
Our Goals
Due to its complex nature, the project was split into multiple components. First, we prototyped a diagnostic tool to help debug Hadoop application failure by providing a clear root cause analysis and save engineering time. Second we purposely inflict failures on a cluster (via a method called chaos testing) and collected the data to understand how certain log messages map to errors. Finally, we examined regular expression as well as natural language processing (NLP) techniques to automatically provide root cause analysis in production.
To document this, we organized the blog in the following sections:
Error Message Analytics Portal
To provide a quick glance at the known root cause.
Datadog Dashboard
To calculate failure rates related to the unknown root cause and known root cause.
Separate infrastructure failure from a missing data failure (missing partition).
Data Access
All relevant logs messages from services like Yarn, Oozie, HDFS, hive server, etc. were collected and stored under an S3 bucket with an expiration policy.
Chaos Data Generation
Using chaos testing, we produced actual errors related to memory, network, etc. This was done to understand relationships between log messages and root cause errors.
A service was made to create an efficient and simple way to run chaos tests and collect its corresponding/related log data.
Diagnostic Message Classification
Due to the simple and repetitive nature of log messages (low in entropy), we built a natural language processing model that classified specific error types of an unknown failure.
Tested the model on the chaos data for the specific workload at Bazaarvoice
Error Message Analytics Portal
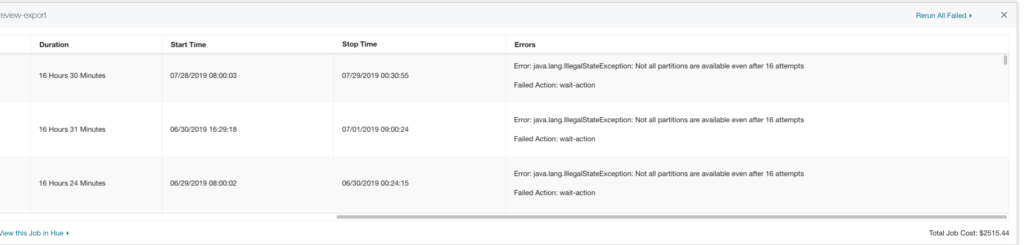
Bazaarvoice provides an internal portal tool for managing analytics applications by the end-users. The following screenshot demonstrates an example message of a “Job failures due to missing data”. This message is caught by using a simple regular expression of the stack trace. A regular expression works because there is only one way a job could fail due to missing data.
DataDog Dashboard
What is a partition?
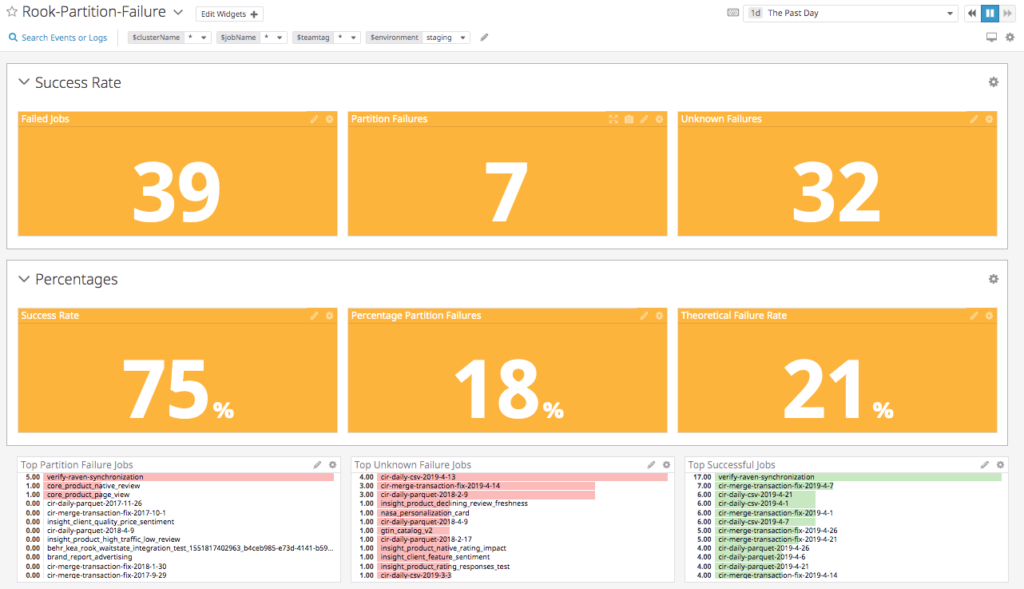
Partitioning is a strategy of dividing a table into related parts based on date, components or other categories. Using a partition, it is easy and faster to query a portion of data. However, the partition a job is querying can sometimes not be available which causes a job to fail by our design. The dashboard below calculates metrics and keeps track of jobs that failed due to an unavailable partition.
The dashboard classifies failed jobs as either a partition failure (late/missing data) or an unknown failure (Hadoop application failure). Our diagnostic tool attempts to find the root cause of the unknown failures since a late or missing data is an easy problem to solve.
Data Access
Since our clusters are powered by Apache Ambari, we leveraged and enhanced Ambari Logsearch Logfeeder to ship logs of relevant services directly to S3 and partitioned the data by as shown in the raw_log of the Directory Tree Diagram below. However, as the dataset got bigger, partitioning was not enough to efficiently query the data. To speed up read performance and to iterate faster, the data was later converted into ORC format.
Convert JSON logs to ORC logs
DROP TABLE IF EXISTS default.temp_table_orc;
CREATE EXTERNAL TABLE default.temp_table_orc (
cluster STRING,
file STRING,
thread_name STRING,
level STRING,
event_count INT,
ip STRING,
type STRING,
...
hour INT,
component STRING
) STORED AS ORC
LOCATION 's3a://<bucket_name>/orc-log/${workflowYear}/${workflowMonth}/${workflowDay}/${workflowHour}/';
INSERT INTO default.temp_table_orc SELECT * FROM bazaar_magpie_rook.rook_log
WHERE year=${workflowYear} AND month=${workflowMonth} AND day=${workflowDay} AND hour=${workflowHour};
Sample Queries for Root Cause Diagnosis
SELECT t1.log_message,
t1.logtime,
t1.level,
t1.type,
t2.Frequency
FROM
(SELECT log_message,
logtime,
TYPE,
LEVEL
FROM
( SELECT log_message,
logtime,
TYPE,
LEVEL,
row_number() over (partition BY log_message
ORDER BY logtime) AS r
FROM bazaar_magpie_rook.rook_log
WHERE cluster_name = 'cluster_name'
AND DAY = 28
AND MONTH=06
AND LEVEL = 'ERROR' ) S
WHERE S.r = 1 ) t1
LEFT JOIN
(SELECT log_message,
COUNT(log_message) AS Frequency
FROM bazaar_magpie_rook.rook_log
WHERE cluster_name = 'cluster_name'
AND DAY = 28
AND MONTH=06
AND LEVEL = 'ERROR'
GROUP BY log_message) t2 ON t1.log_message = t2.log_message
WHERE t1.logtime BETWEEN '2019-06-28 13:05:00' AND '2019-06-28 13:30:00'
ORDER BY t1.logtime
LIMIT 400;
SELECT log_message, logtime, type
FROM bazaar_magpie_rook.rook_log WHERE level = 'ERROR' AND type != 'logsearch_feeder' AND logtime BETWEEN '2019-06-24 09:05:00' AND '2019-06-24
12:30:10'
ORDER BY logtime
LIMIT 1000;
SELECT log_message, COUNT(log_message) AS Frequency
FROM bazaar_magpie_rook.rook_log
WHERE cluster_name = 'dev-blue-3' AND level = 'ERROR' AND logtime BETWEEN '2019-06-27 13:50:00' AND '2019-06-29 14:30:00'
GROUP BY log_message
ORDER BY COUNT(log_message) DESC
LIMIT 10;
Chaos Data Generation
The chaos data generation process makes up a bulk of this project as well is the most important. It stems from the process of chaos testing to experiment on software and infrastructure in order to understand the systems ability to withstand unexpected or turbulent conditions. This concept of testing was first introduced by Netflix in 2011. The following pseudocode explains how it works.
Submit a normal job through an API on a specific cluster
Create a list of IP addresses for all the testable nodes in that cluster (such as the workers nodes).
Once we have all associated nodes, inject failures into them (stress test memory or network)
While the job is not done
Let the job run
At this point, the job has either failed or succeeded
Stop all stress tests
Gather the job details such as start time, end time, status, and most importantly its associated stress test type (memory, packet_corruption, etc.).
Store job details and its report in JSON format
We followed the same process to generate chaos data on different types of injected failures such as:
High Memory Utilization on the Host
Packet Corruption
Packet Loss
High Memory Util on a Container
While there are certainly more errors the model is capable of learning and classifying, for the purpose of prototyping we kept the type of failures to 2-3 categories.
Diagnostic Message Classification
In this section, we explore 2 types of error classification methods, a simple regex and supervised learning.
Short Term Solution with Regex
There are many ways to analyze text for different patterns. One of these ways is called Regular Expression Matching (regex). Regex is “special strings representing a pattern to be matched in search operation”. One use of regex is finding a keyword like “partition”. When a job fails due to missing partitions its error message usually looks something like this “Not all partitions are available even after 16 attempts“. The regex for this specific case would look like \W*((?i)partition(?-i))\W* .
A regex log parser could easily be able to identify this error and do what is necessary to fix the problem. However, the power of regex is very limiting when it comes to analyzing complex log messages and stack traces. When we find a new error, we would have to manually hardcode a new regular expression to pattern match the new error type which is very error-prone and tedious in the long run.
Since the Hadoop eco-system includes many components, there are many combinations of log messages that can be produced; a simple regex parser would be difficult to work here because it can not process general similarities between different sentences. This is where natural language processing helps.
Long Term Solution with Supervised Learning
The idea behind this solution is to use natural language processing to process log messages and supervised learning to learn and classify errors. This model should work well with log data vs. normal language due since machine logs are more structured and low in entropy. You can think of entropy as a measure of how unstructured or random a set of data is. The English language tends to have high entropy relative to machine logs due to its sometimes illogical sentence structure. On the other hand, machine-generated log data is very repetitive which makes it easier to model and classify.
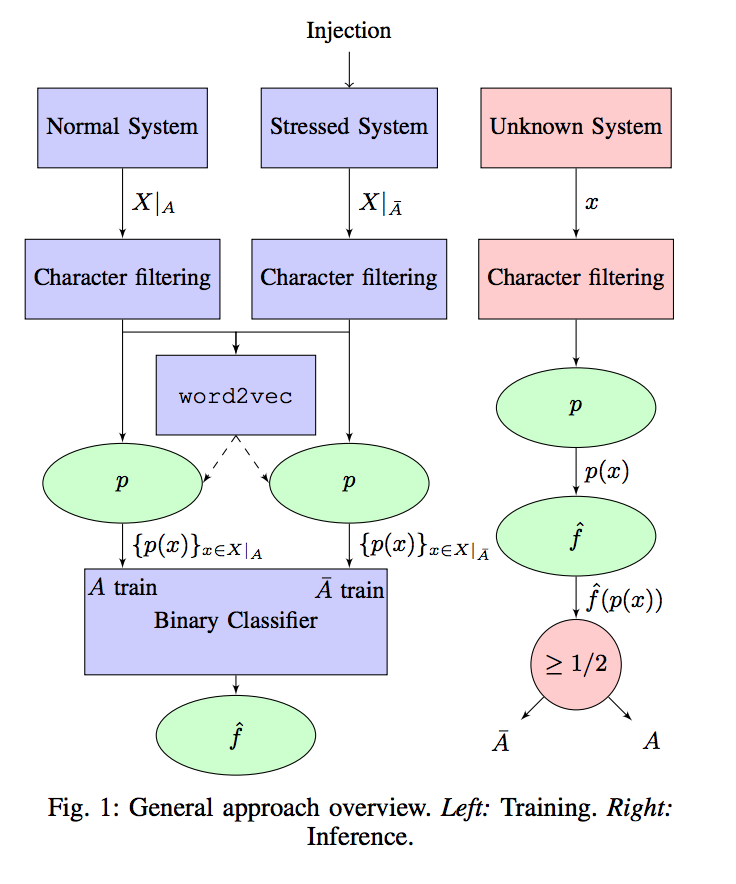
Our model required pre-processing of logs which are called tokenization. Tokenization is the process of taking a set of text and breaking it up into its individual words or tokens. Next, the set of tokens were used to model their relationship in high dimensional space using Word2Vec. Word2Vec is a widely popular model used for learning vector representation of words called, “word embeddings” (word2vec). Finally, we use the vector representation to train a simple logistic regression classifier using the chaos data generated earlier. The diagram below shows a similar training processing from Experience Report: Log Mining using Natural Language Processing and Application to Anomaly Detection by Christophe Bertero, Matthieu Roy, Carla Sauvanaud and Gilles Tredan.
In contrast to the diagram above, since we only trained the classifier on error logs, it was not possible to classify a normal system as it should produce no error logs. Instead, we trained the data on different types of stressed systems. Using the dataset generated by chaos testing, we were able to identify the root cause for each of the error message for each failed job. This allowed us to make our training dataset as shown below. We split our dataset into a simple 70% training and 30% for testing.
Subsequently, each log message was tokenized to create a word vector. All the tokens were inputted into a pre-trained word2vec model which mapped out each word in a vector space, creating a word embedding. Each line was represented as a list of vectors and an average of all the vectors in a log message represents the feature vector in high dimensional space. We then inputted each feature vector and its labels into a classification algorithm such as logistic regression or random forest to create a model that could predict the root cause error from a logline. However, since failure often contains multiple error log messages, it would not be logical to simply reach a root cause conclusion from just a single line of the log from a long error log. A simple way to tackle this problem would be to window the log and input the individual lines from the window into the model and output the final error as the most common error outputted by all the lines in a window. This is a very naive way of breaking apart long error log so more research would have to be done to process error logs without losing the valuable insight of their dependent messages.
Below are a few examples of error log messages and their tokenized version.
Example Raw Log
java.lang.RuntimeException: org.apache.thrift.transport.TSaslTransportException: No data or no sasl data in the stream at org.apache.thrift.transport.TSaslServerTransport$Factory.getTransport(TSaslServerTransport.java:219)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:269)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_191] Caused by: org.apache.thrift.transport.TSaslTransportException: No data or no sasl data in the stream at org.apache.thrift.transport.TSaslTransport.open(TSaslTransport.java:328)
at org.apache.thrift.transport.TSaslServerTransport.open(TSaslServerTransport.java:41) ~[hive-exec-3.1.0.3.1.0.0-78.jar:3.1.0-SNAPSHOT] at org.apache.thrift.transport.TSaslServerTransport$Factory.getTransport(TSaslServerTransport.java:216)
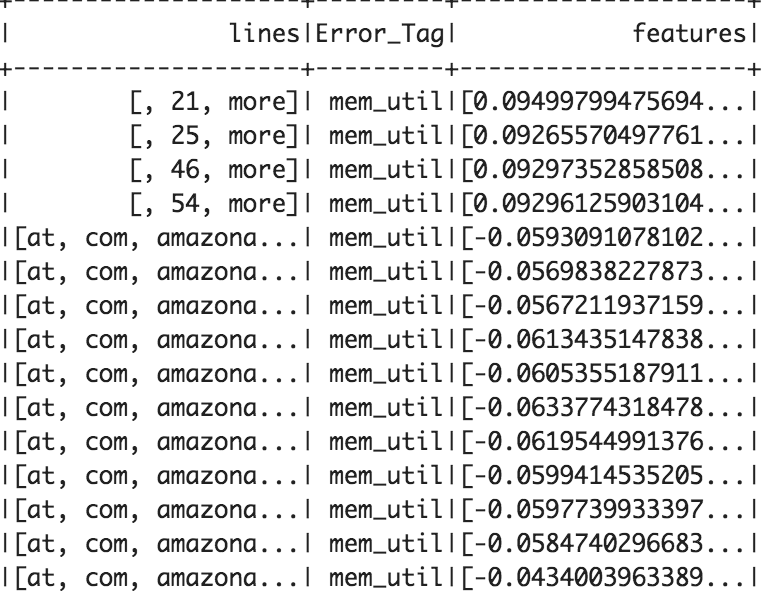
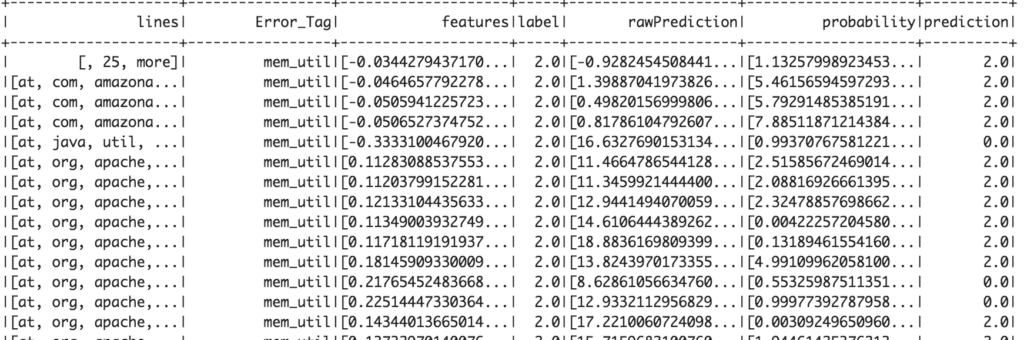
The model accurately predicted the root cause of failed job with 99.3% accuracy in our test dataset. At an initial glance, the metrics calculated on the test data look very promising. However, we still need to evaluate its efficiency in production to get a more accurate picture. The initial success in this proof of concept warrants further experimentation, testing, and investigation for using NLP to classify errors.
Training Data 70% (Top 20 Rows)
Test Data Results 30% (Top 20 Rows)
Conclusion
In order to implement this tool in production, data engineers will have to automate certain aspects of the data aggregation and model building pipeline
Self Reporting Errors
A machine learning model is only as good as its data. For this tool to be robust and accurate, any time engineers encounter a new error or an error that the model does not know about, they should report their belief of the root cause so the corresponding errors logs get tagged with the specific root cause error. For instance, when a job fails for a similar reason, the model will be able to diagnose and classify its error type. This can be done through a simple API, form, Hive query that takes in the job id and its assumed root_cause. The idea behind is this that by creating a form, we could manual label log messages and errors in case the classifier fails to correctly diagnose the true problem.
The self-reported error should take the form of the chaos error to ensure the existing pipeline will work.
Automating Chaos Data Generation
The chaos tests should run on a regular basis in order to keep the model up to date. This could be done by creating a Jenkins job that automatically runs on a regular cadence. Often times, running a stress test will make certain nodes to be unhealthy. It causes our automation to be unable to SSH into the nodes again to stop the stress test such as when the stress test is interfering with connectivity to the node (see the error below). This can be solved by creating a time limit for the stress test, so the script does not have to ssh again once the job has finished. In the long run, as the self-reported errors grow, the model should rely on chaos test generated test less. Chaos tests produce logs for very extreme situations which could be not typical for a normal production environment.
java.lang.RuntimeException: Unable to setup local port forwarding to 10.8.100.144:22
at com.bazaarvoice.rook.infra.util.remote.Gateway.connect(Gateway.java:103)
at com.bazaarvoice.rook.infra.regress.yarn.RootCauseTest.kill_memory_stress_test(RootCauseTest.java:174)
Recently, during a holiday lull, I decided to look at another way of modeling event stream data (for the purposes of anomaly detection).
I’ve dabbled with (simplistic) event stream models before but this time I decided to take a deeper look at Twitter’s anomaly detection algorithm [1], which in turn is based (more or less) on a 1990 paper on seasonal-trend decomposition [2].
To round it all off, and because of my own personal preference for on-line algorithms with minimal storage and processing requirements, I decided to blend it all with my favorite on-line fading-window statistics math. On-line algorithms operate with minimal state and no history, and are good choices for real-time systems or systems with a surplus of information flowing through them (https://en.wikipedia.org/wiki/Online_algorithm)
The Problem
The high-level overview of the problem is this: we have massive amounts of data in the form of web interaction events flowing into our system (half a billion page views on Black Friday, for example), and it would be nice to know when something goes wrong with those event streams. In order to recognize when something is wrong we have to be able to model the event stream to know what is right.
A typical event stream consists of several signal components: a long-term trend (slow increase or decrease in activity over a long time scale, e.g. year over year), cyclic activity (regular change in behavior over a smaller time scale, e.g. 24 hours), noise (so much noise), and possible events of interest (which can look a lot like noise).
This blog post looks at extracting the basic trend, cycle, and noise components from a signal.
Note: The signals processed in this experiment are based on real historical data, but are not actual, current event counts.
The Benefit
The big payback of having a workable model of your system is that when you compare actual system behavior against expected behavior, you can quickly identify problems — significant spikes or drops in activity, for example. These could be from DDOS attacks, broken client code, broken infrastructure, and so forth — all of which are better to detect sooner than later.
Having accurate models can also let you synthesize test data in a more realistic manner.
The Basic Model
Trend
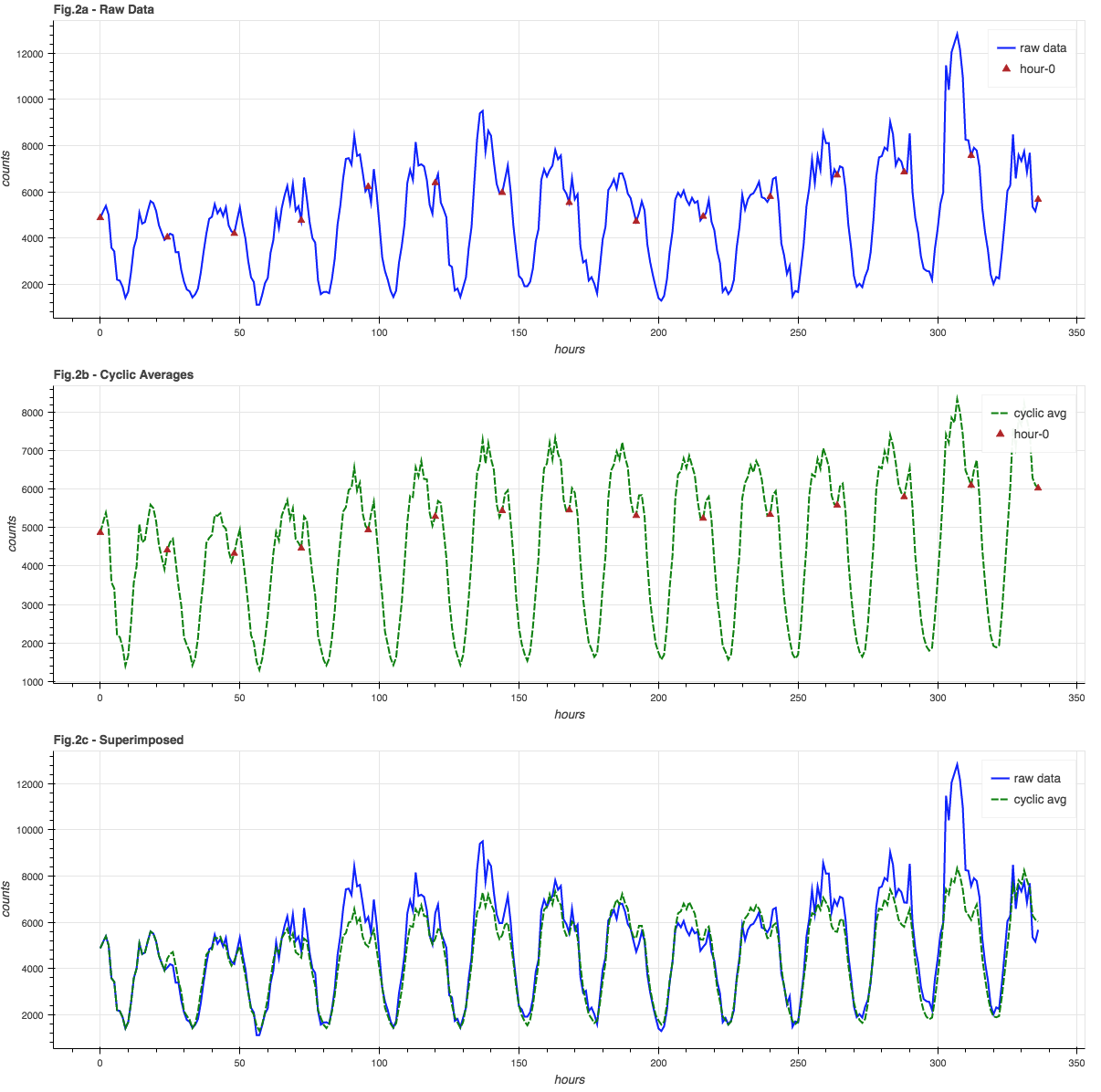
A first approximation of modeling the event stream comes in the form of a simple average across the data, hour-by-hour:
The blue line is some fairly well-behaved sample data (events per hour) and the green lines are averages across different time windows. Note how the fastest 1-day average takes on the shape of the event stream but is phase-shifted; it doesn’t give us anything useful to test against. The slowest 21-day average gives us a decent trend line for the data, so if we wanted to do a rough de-trending of the signal we could subtract this mean from the raw signal. Twitter reported better results using the median value for de-trending but since I’m not planning on de-trending the signal in this exploration, and median calculations don’t fit into my lightweight on-line philosophy, I’m going to stay with the mean as trend.
Cycle
While the fast 1-day average takes on the shape of the signal, it is phase shifted and is not a good model of the signal’s cyclic nature. The STL seasonal-trend technique(see [2]) models the cyclic component of the signal (“seasonal” in the paper, but our “season” is a 24-hour span) by creating multiple averages of the signal, one per cycle sub-series. What this means for our event data is that there will be one average for event counts from 1:00am, another average for 2:00am, and so forth, for a total of 24 running averages:
The blue graph in Figure 2a shows the raw data, with red triangles at “hour 0″… these are all averaged together to get the “hour 0” averages in the green graph in Figure 2b. The green graph is the history of all 24 hourly sub-cycle averages. It is in-phase with and closely resembles the raw data, which is easier to see in Figure 2c where the signal and cyclic averages are super-imposed.
A side effect of using a moving-window average is that the trend information is automatically incorporated into the cyclic averages, so while we can calculate an overall average, we don’t necessarily need to.
Noise
The noise component is the signal minus the cyclic model and the seasonal trend. Since our online cyclic model incorporates trending already, we can simple subtract the two signals from Figure 2c to give us the noise component, shown in Figure 3:
Some Refinements
Now that we have a basic model in place we can look at some refinements.
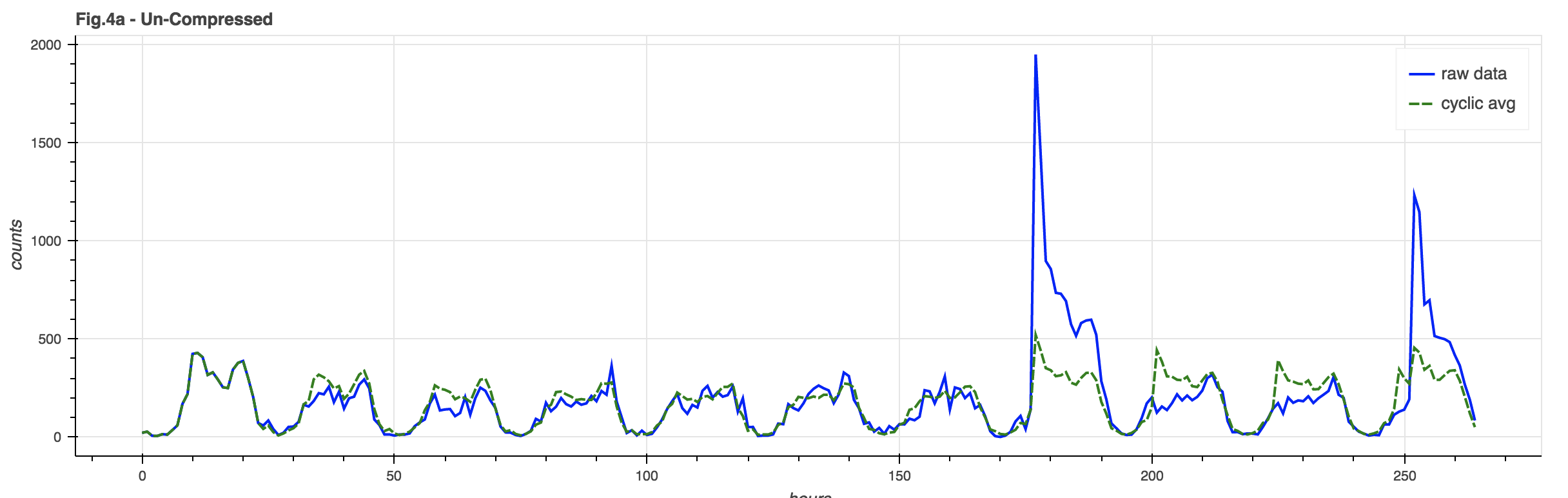
Signal Compression
One problem with the basic model is that a huge spike in event counts can unduly distort the underlying cyclic model. A mild version of this can be seen in Figure 4a, where the event spike is clearly reflected in the model after the spike:
By taking a page out of the audio signal compression handbook, we can squeeze our data to better fit within a “standard of deviation”. There are many different ways to compress a signal, but the one illustrated here is arc-tangent compression that limits the signal to PI/2 times the limit factor (in this case, 4 times the standard deviation of the signal trend):
There is still a spike in the signal but its impact on the cyclic model is greatly reduced, so post-event comparisons are made against a more accurate baseline model.
Event Detection
Now we have a signal, a cyclic model of the signal, and some statistical information about the signal such as its standard deviation along the hourly trend or for each sub-cycle.
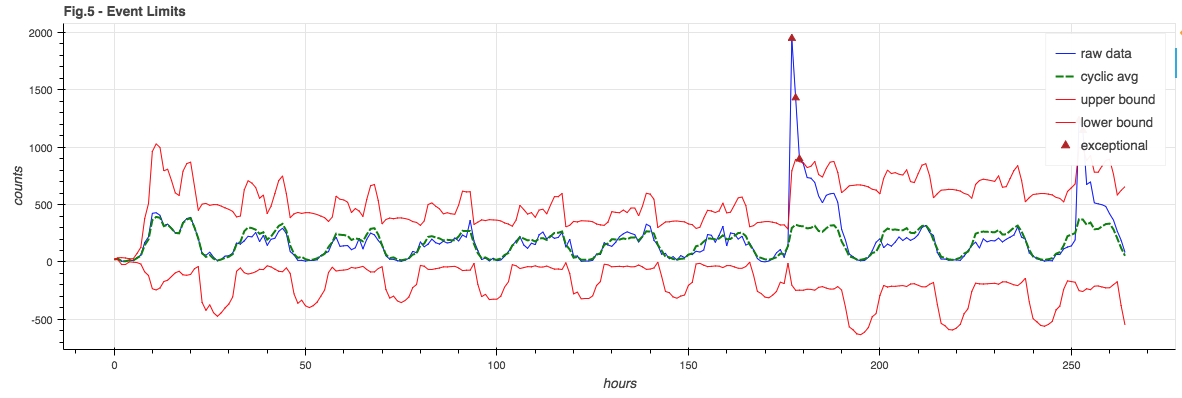
Throwing it all into a pot and mixing, we choose error boundaries that are a combination of the signal model and the sub-cycle standard deviation and note any point where the raw signal exceeds the expected bounds:
Event Floor
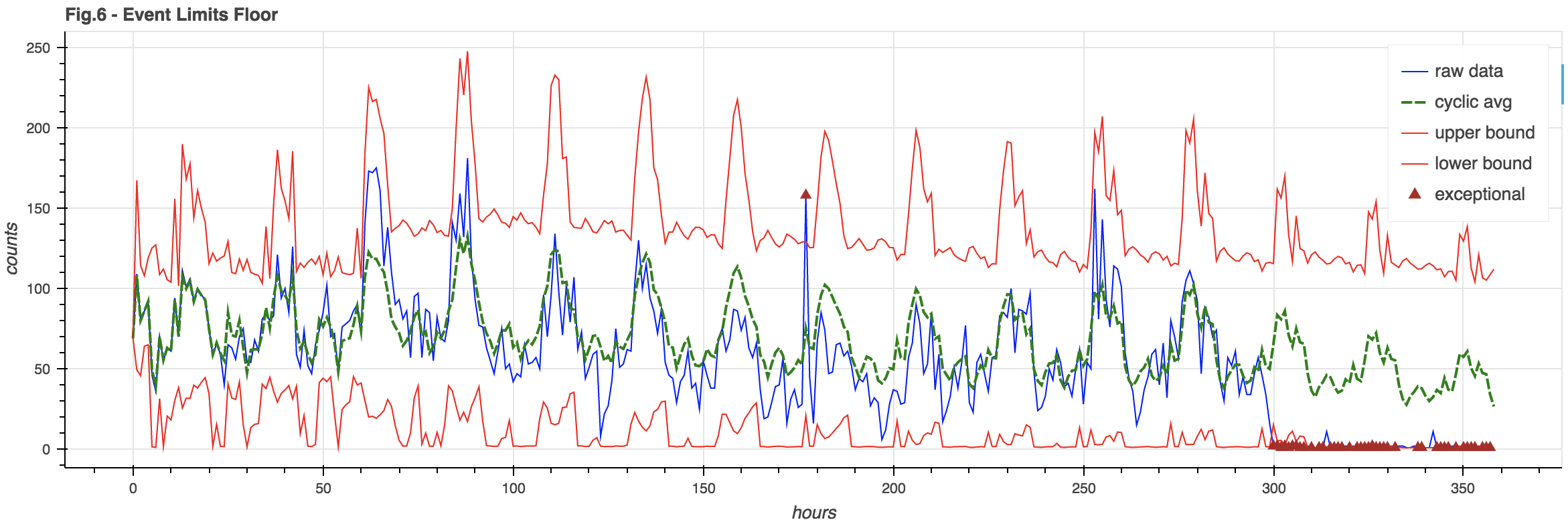
You may note in Figure 5 how the lower bound goes negative. This is silly – you can’t have negative event counts. Also, for a weak signal where the lower bound tends to be negative, it would be hard to notice when the signal fails completely – as it’s still in bounds.
It can be useful to enforce an event floor so we can detect the failure of a weak signal. This floor is arbitrarily chosen to be 3% of the cyclic model (though it could also be a hard constant):
The End
Playing with data is a ton of fun, so all of the Python code that generated these examples (plus a range of sample data) can be found in GitHub here:
As Engineers, we often like nice clean solutions that don’t carry along what we like to call technical debt. Technical debt literally is stuff that we have to go back to fix/rewrite later or that requires significant ongoing maintenance effort. In a perfect world, we fire up the the new platform and move all the traffic over. If you find that perfect world, please send an Uber for me. Add to this the scale of traffic we serve at Bazaarvoice, and it’s obvious it would take time to harden the new system.
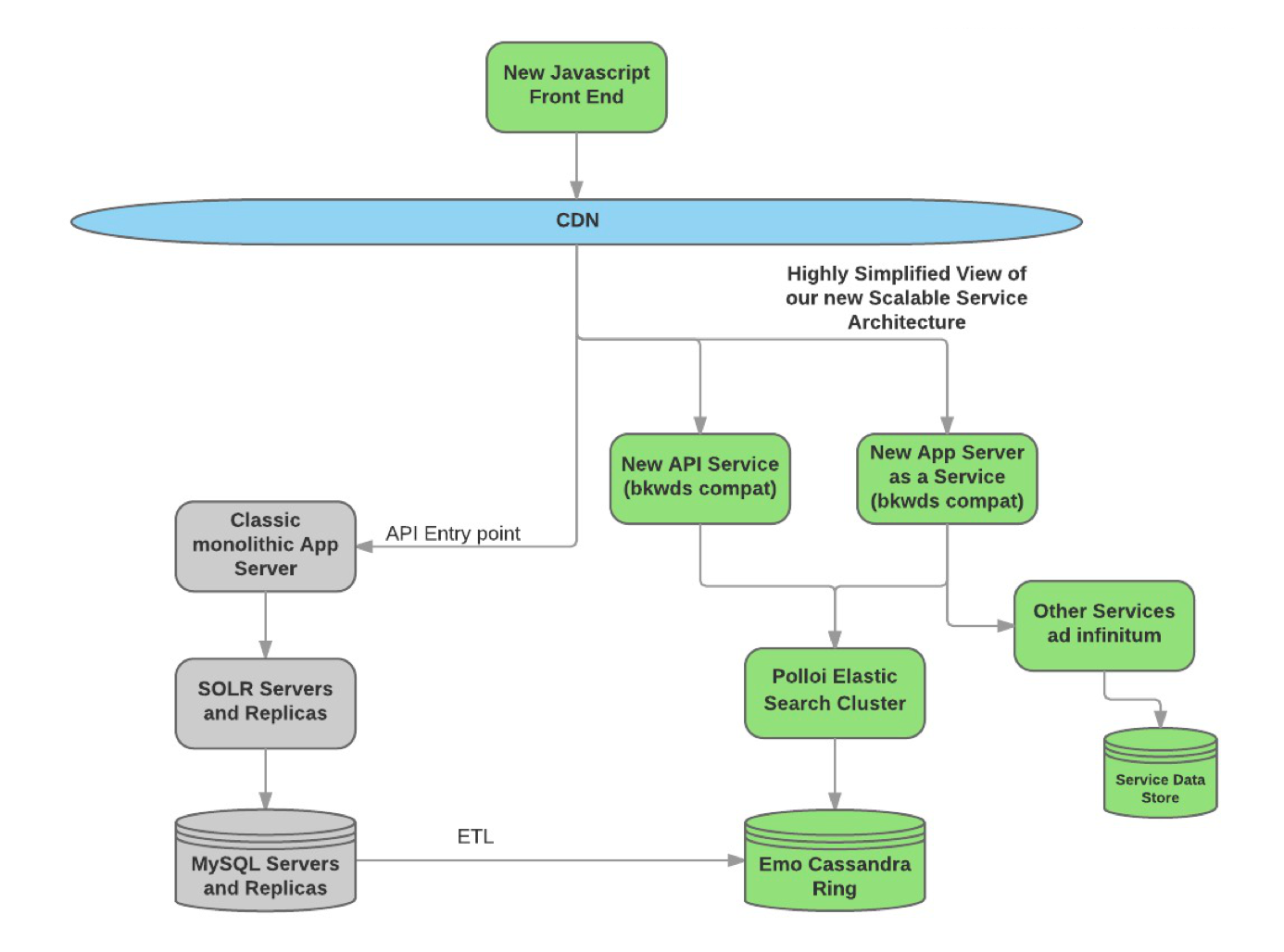
The secret to how we pulled this off lies in the architecture choices to break apart the challenge into two parts: frontend and backend. While we reengineered the front-end into the the new javascript solution, there were still thousands of customers using the template-based front end. So, we took the original server side rendering code and turned it into a service talking to our new Polloi service. This enabled us to handle request from client sites exactly like the Classic original system.
Also, we created a service improved upon the original API but was compatible from a specific version forward. We chose to not try to be compatible for all version for all time, as all APIs go through evolution and deprecation. We naturally chose the version that was compatible with the new Javascript front end. With these choices made, we could independently decide when and how to move clients to the new backend architecture irrespective of the front-end service they were using.
A simplified view of this architecture looks like this:
With the above in place, we can switch a Javascript client to use the new version of the API through just changing the endpoint of the API key. For a template-based client, we can change the endpoint to the new referring service through a configuration in our CDN Akamai.
Testing for compatibility is a lot of work, though not particularly difficult. API compatibility is pretty straight forward, which testing whether a template page renders correctly is a little more involved especially since those pages can be highly customized. We found the most effective way to accomplish the later since it was a one time event was with manual inspection to be sure that the pages rendered exactly the same on our QA clusters as they did in the production classic system.
Success we found early on was based on moving cohorts of customers together to the new system. At first we would move a few at a time, making absolutely sure the pages rendered correctly, monitoring system performance, and looking for any anomalies. If we saw a problem, we could move them back quickly through reversing the change in Akamai. At first much of this was also manual, so in parallel, we had to build up tooling to handle the switching of customers, which even included working with Akamai to enhance their API so we could automate changes in the CDN.
From moving a few clients at a time, we progressed to moving over 10s of clients at a time. Through a tremendous engineering effort, in parallel we improved the scalability of our ElasticSearch clusters and other systems which allowed us to move 100s of clients at a time, then 500 clients at time. As of this writing, we’ve moved over 5,000 sites and 100% of our display traffic is now being served from our new architecture.
More than just serving the same traffic as before, we have been able to move over display traffic for new services like our Curations product that takes in and processes millions of tweets, Instagram posts, and other social media feeds. That our new architecture could handle without change this additional, large-scale use case is a testimony to innovative engineering and determination by our team over the last 2+ years. Our largest future opportunities are enabled because we’ve successfully been able to realize this architectural transformation.
Rearchitecting the Team
In addition to rearchitecting the service to scale, we also had to rearchitect our team. As we set out on this journey to rebuild our solution into a scalable, cloud based service oriented architecture, we had to reconsider the very way our teams are put together. We reimagined our team structure to include all the ingredients the team needs to go fast. This meant a big investment in devops – engineers that focus on new architectures, deployment, monitoring, scalability, and performance in the cloud.
A critical part of this was a cultural transformation where the service is completely owned by the team, from understanding the requirements, to code, to automated test, to deployment, to 24×7 operation. This means building out a complete monitoring and alerting infrastructure and that the on-call duty rotated through all members of the team. The result is the team becomes 100% aligned around the success of the service and there is no “wall” to throw anything over – the commitment and ownership stays with the team.
For this team architecture to succeed, the critical element is to ensure the team has all the skills and team players needed to succeed. This means platform services to support the team, strong product and program managers, talented QA automation engineers that can build on a common automation platform, gifted technical writers, and of course highly talented developers. These teams are built to learn fast, build fast, and deploy fast, completely independent of other teams.
Supporting the service-oriented teams, a key element is our Platform Infrastructure team we created to provide a common set of cloud services to support all our teams. Platform Infrastructure is responsible for the virtual private cloud (VPC) supporting the new services running in amazon web services. This team handles the overall concerns of security, network, service discovery, and other common services within the VPC. They also set up a set of best practices, such as ensuring all cloud instances are tagged with the name of the team that started them.
To ensure the best practices are followed, the platform infrastructure team created “Beavers” (a play on words describing a engineer at Bazaarvoice, a “BVer”). An idea borrowed from Netflix’s chaos monkeys, these are automated processes that run and examine our cloud environment in real time to ensure the best practices are followed. For example, the “Conformity Beaver” runs regularly and checks to make sure all instances and buckets are tagged with team names. If it finds one that is not, it infers the owner and emails team aliases of the problem. If not corrected, Conformity Beaver can terminate the instance. This is just one example of the many Beavers we have created to help maintain consistency in a world where we have turned teams lose to move as quickly as possible.
An additional key common capability created by the Platform Infrastructure team is our Badger monitoring services. Badger enables teams to easily plug in a common healthcheck monitoring capability and can automatically discover nodes as they are started in the cloud. This service enables teams to easily implement these healthcheck that is captured in a common place and escalated through a notification system in the event of a service degradation.
The Proof is in the Pudding
The Black Friday and Holiday shopping season of 2015 was one of the smoothest ever in the history of Bazaarvoice while serving record traffic. From Black Friday to Cyber Monday, we saw over 300 million visitors. At peak on Black Friday, we were seeing over 97,000 requests per second as we served up over 2.6 billion review impressions, a 20% increase over the year before. There have been years of hard work and innovation that preceded this success and it is a testimony to what our new architecture is capable of delivering.
Keys to success
A few ingredients we’ve found to be important to successfully pull off a large scale rearchitecture such as described here:
Brilliant people. There is no replacement for brilliant engineers who are fearless in adopting new technologies and tackling what some will say can’t be done.
Strong leaders – and the right leaders at the right time. Often the leaders that sell the vision and get an undertaking like this going will need to be supplemented with those that can finish strong.
Perseverance and Determination – building a new platform using new technologies is going to be a much bigger challenge than you can estimate, requiring new skills, new approaches, and lots of mistakes. You must be completely determined and focused on the end game.
Tie back to business benefit – keep business informed of the benefits and ensuring that those benefits can be delivered continuously rather than a big bang. It will be a large investment and it is important that the business see some level of return as quickly as possible.
Make space for innovation – create room for engineers to learn and grow. We support this through organizing hackathons and time for growth projects that benefit the individual, team, and company.
Reachitecture is a Journey
One piece of advice: don’t be too critical of yourself along the way; celebrate each step of the reachitecture journey. As software engineers, we are driven to see things “complete”, wrapped up nice and neat, finished with a pretty bow. When replacing an existing system of significant complexity, this ideal is a trap because in reality you will never be complete. It has taken us over 3 years of hard work to reach this point, and there are more things we are in the process of moving to newer architectures. Once we complete the things in front of us now, there will be more steps to take since we live in an ever evolving landscape. It is important to remember that we can never truly be complete as there will be new technologies, new architectures that deliver more capabilities to your customers, faster, and at a lower cost. Its a journey.
Perhaps that is the reason many companies can never seem to get started. They understandably want to know “When will it be done?” “What is it going to cost?”, and the unpopular answers are of course, never and more than you could imagine. The solution to this puzzle is to identify and articulate the business value to be delivered as a step in the larger design of a software platform transformation. Trouble is of course, you may only realistically be able to design the first few steps of your platform rearchitecture, leaving a lot of technical uncertainty ahead. Get comfortable with it and embrace it as a journey. Engineer solid solutions in a service oriented way with clear interfaces and your customers will be happy never knowing they were switched to the next generation of your service.
At Bazaarvoice, we’ve pulled off an incredible feat, one that is such an enormous task that I’ve seen other companies hesitate to take on. We’ve learned a lot along the way and I wanted to share some of these experiences and lessons in hopes they may benefit others facing similar decisions.
The Beginning
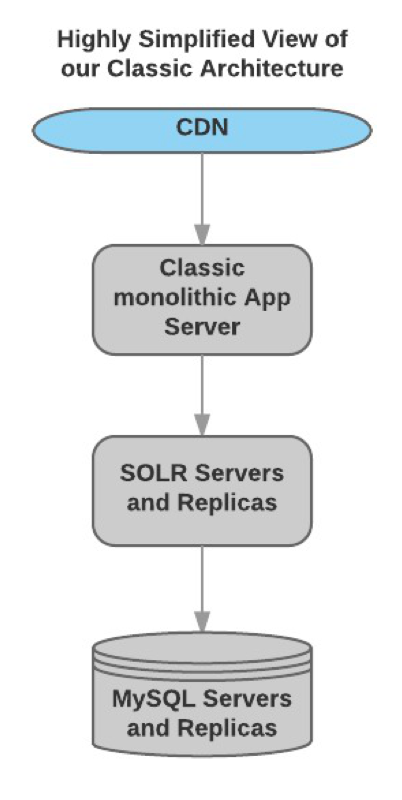
Our original Product Ratings and Review service served us well for many years, though eventually encountered severe scalability challenges. Several aspects we wanted to change: a monolithic Java code base, fragile custom deployment, and server-side rendering. Creative use of tenant partitioning, data sharding and horizontal read scaling of our MySQL/Solr based architecture allowed us to scale well beyond our initial expectations. We’ve documented how we have accomplished this scaling on our developer blog in several past posts if you’d like to understand more. Still, time marches on and our clients have grown significantly in number and content over the years. New use cases have come along since the original design: emphasis on the mobile user and responsive design, accessibility, the emphasis on a growing network of consumer generated content flowing between brands and retailers, and the taking on of new social content that can come in floods from Twitter, Instagram, Facebook, etc.
As you can imagine, since the product ratings and reviews in our system are displayed on thousands of retailer and brand websites around the world, the read traffic from review display far outweighs the write traffic from new reviews being created. So, the addition of clusters of Solr servers that are highly optimized for fast queries was a great scalability addition to our solution.
A highly simplified diagram of our classic architecture:
However, in addition to fast review display when a consumer visited a product page, another challenge started emerging out of our growing network of clients. This network is comprised of Brands like Adidas and Samsung who collect reviews on their websites from consumers who purchased the product and then want to “syndicate” those reviews to a set of retailer ecommerce sites where shoppers can benefit from them. Aside from the challenges of product matching which are very interesting, under the MySQL architecture this could mean the reviews could be copied over and over throughout this network. This approach worked for several years, but it was clear we needed a plan for the future.
As we grew, so did the challenge of an expanding volume of data in the master databases to serve across an expanding network of clients. This, together with the need to deliver more front-end web capability to our customers, drove us to what I hope you will find is a fascinating story of rearchitecture.
The Journey Begins
One of the first things we decided to tackle was to start moving analytics and reporting off the existing platform so that we could deliver new insights to our clients showing how reviews are used by shoppers in their purchase decisions. This choice also enabled us to decouple the architecture and spin up parallel teams to speed delivery. To deliver these capabilities, we adopted big data architectures based on Hadoop and HBase to be able to assimilate hundreds of millions of web visits into analytics that would paint the full shopper journey picture for our clients. By running map reduce over the large set of review traffic and purchase data, we are able to give our clients insight into these shopper behaviors and help our clients better understand the return on investment they receive from consumer generated content. As we built out this big data architecture, we also saw the opportunity to offload reporting from the review display engine. Now, all our new reporting and insight efforts are built off this data and we are actively working to move existing reporting functionality to this big data architecture.
On the front end, flexibility and mobile was a huge driver in our rearchitecture. Our original template-driven, server-side rendering can provide flexibility, but that ultimate flexibility is only required in a small number of use cases. For the vast majority, a client-side rendering via javascript with behavior that can be configured through a simple UI would yield a better mobile-enabled shopping experience that’s easier for clients to control. We made the call early on not to try to force migration of clients from one front end technology to another. For one thing, it’s not practical for a first version of a product to be 100% feature function capable to the predecessor. For another, there was just simply no reason to make clients choose. Instead, as clients redesigned their sites and as new clients were onboard, they opt’ed in to the new front end technology.
We attracted some of the top javascript talent in the country to this ambitious undertaking. There are some very interesting details of the architecture we built that have been described on our developer blog and that are available as open source projects on in our bazaarvoice github organization. Look for the post describing our Scoutfile architecture in March of 2015. The BV team is committed to giving back to the Open Source community and we hope this innovation helps you in your rearchitecure journey.
On the backend, we took inspiration from both Google and Netflix. It was clear that we needed to build an elastic, scalable, reliable, cloud-based data store and query layer. We needed to reorganize our engineering team into autonomous service oriented teams that could move faster. We needed to hire and build new skills in new technologies. We needed to be able to roll this out as transparently as possible to our clients while serving live shopping traffic so no one knows its happening at all. Needless to say, we had our work cut out for us.
For the foundation of our new architecture, we chose Cassandra, an Open Source NoSQL data solution based on influence of ideas from Google and their BigTable architecture. Cassandra had been battle hardened at Netflix and was a great solution for a cloud resilient, reliable storage engine. On this foundation we built a service we call Emo, originally intended for sentiment analysis. As we made progress towards delivery, we began to understand the full potential of Cassandra and its NoSQL based architecture as our primary display storage.
With Emo, we have solved the potential data consistency issues of Cassandra and guarantee ACID database operations. We can also seamlessly replicate and coordinate a consistent view of all the rating and review data across AWS availability zones worldwide, providing a scalable and resilient way to serve billions of shoppers. We can also be selective in the data that replicates for example from the European Union (EU) so that we can provide assurances of privacy for EU based clients. In addition to this consistency capability, Emo provides a databus that allows any Bazaarvoice service to listen for the kinds of changes the service particularly needs, perfect for a new service oriented architecture. For example, a service can listen for the event of a review passing moderation which would mean that it should now be visible to shoppers.
While Emo/Cassandra gave us many advantages, its NoSQL query capability is limited to what Cassandra’s key-value paradigm. We learned from our experience with Solr that having a flexible, scalable query layer on top of the master datastore resulted in significant performance advantages for calculating on-demand results of what to display during a shopper visit. This query layer naturally had to provide the distributed advantages to match Emo/Cassandra. We chose ElasticSearch for our architecture and implemented a flexible rules engine we call Polloi to abstract the indexing and aggregation complexities away from engineers on teams that would use this service. Polloi hooks up to the Emo databus and provides near real time visibility to changes flowing into Cassandra.
The rest of the monolithic code base was reimplemented into services as part of our service oriented architecture. Since your code is a direct reflection of the team, as we took on this challenge we formed autonomous teams that owned everything full cycle from initial conception to operation in production. We built the teams with all the skills needed for success: product owners, developers, QA engineers, UX designers (for front end), DevOps engineers, and tech writers. We built services that managed the product catalog, UI Configuration, syndication edges, content moderation, review feeds, and many more. We have many of these rearchitected services now in production and serving live traffic. Some examples include services that perform the real time calculation of what Brands are syndicating consumer generated content to which Retailers, services that process client product catalog feeds for 100s of millions of products, new API services, and much more.
To make all of the above more interesting, we also created this service-oriented architecture to leverage the full power of Amazon’s AWS cloud. It was clear we had the uncommon opportunity to build the platform from the ground up to run in the cloud with monitoring, elastic resiliency, and security capabilities that were unavailable in previous data center environments. With AWS, we can take advantage of new hardware platforms with a push of a button, create multi datacenter failover capabilities, and use new capabilities like elastic MapReduce to deliver big data analytics to our clients. We build auto-scaling groups that allow our services to automatically add compute capacity as client traffic demands grow. We can do all of this with a highly skilled team that focuses on delivering customer value instead of hardware procurement, configuration, deployment, and maintenance.
So now after two plus years of hard work, we have a modern, scalable service-oriented solution that can mirror exactly the original monolithic service. But more importantly, we have a production hardened new platform that we will scale horizontally for the next 10 years of growth. We can now deliver new services much more quickly leveraging the platform investment that we have made and deliver customer value at scale faster than ever before.
So how did we actually move 300 million shoppers without them even knowing? We’ll take a look at this in an upcoming post!
Preparing for the Holiday season is a year round task for all of us here at Bazaarvoice. This year we saw many retailers extending their seasonal in-store specials to their websites as well. We also saw retailers going as far as closing physical stores on Thanksgiving (Nordstrom, Costco, Home Depot, etc.) and Black Friday (REI). Regardless of which of the above strategies were taken, the one common theme amongst retailers was the increase in online sales.
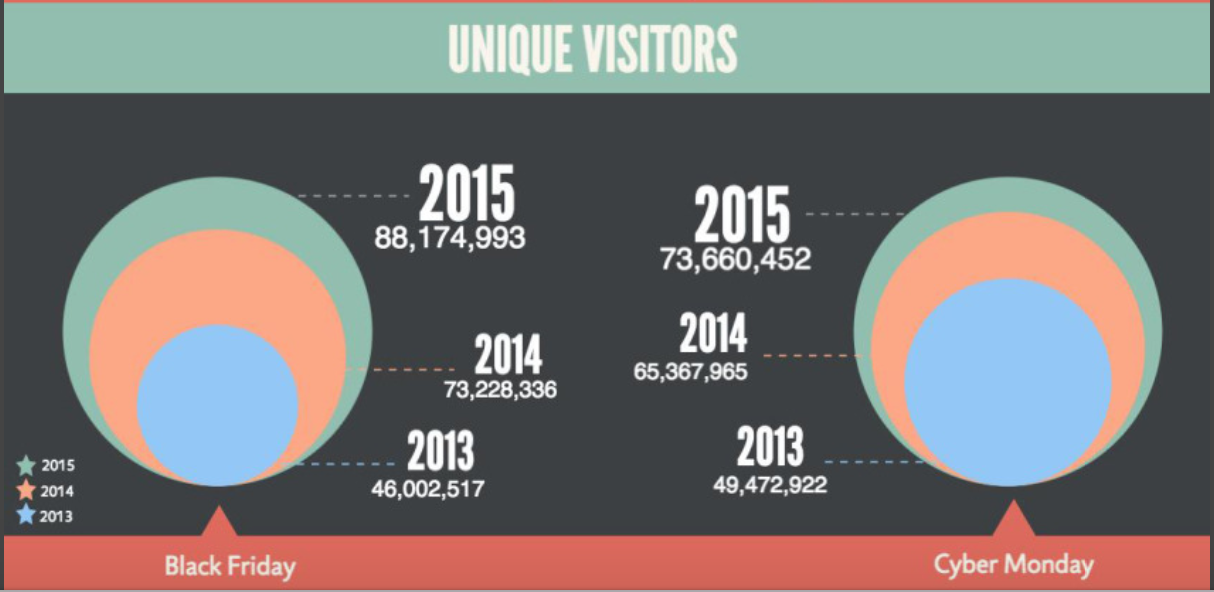
So here are just a few of the metrics that the Bazaarvoice network saw in the busiest week of online shopping:
Unique Visitors throughout 2013-2015
Pageviews and Impressions 2013-2015
So how does the Bazzarvoice team prepare the Holiday Season?
As soon as the online traffic settles from the peak levels, the R&D team begins preparing for the next year’s Holiday Season. First by looking back at the numbers and how we did as a team through various retrospectives. Taking inventory of what went well and what we can improve upon for the next year. Before you know it the team gets together in June to being preparations for the next years efforts. I want to touch on just a few of the key areas the team focused on this past year to prepare for a successful Holiday Season:
Client communication
Disaster Recovery
Load/Performance Testing
Freeze Plan
Client Communication
One key improvement this year was client communication both between R&D and other internal teams as well as externally to clients. This was identified as an area we could improve from last year. Internally a response communication plan was developed. This plan makes sure that key representatives in R&D and support teams were on call at all times and everyone understands escalation paths and procedures should an issue occur. It was then the responsibility of the on call representative to communicate any needs with the different engineers and client support staff. The on call period lasted from November 24th to Tuesday December the 1st.
A small focused team was identified for creation and delivery of all client communication. As early as August, “Holiday Preparedness” communications were delivered to clients informing them of our service level objectives. Monthly client communications followed containing load target calculations, freeze plans, disaster recover preparations, as well as instructions on how to contact Bazaarvoice in the event of an issue as well as how we would communicate current status of our network during this critical holiday season.
Internally there was also an increased emphasis on the creation and evaluation of runbooks. Runbooks are ‘play by play’ instructions which engineers should carry out for different scenarios. The collection of procedures and operations were vital in the teams disaster recovery planning.
Disaster Recovery
To improve our operational excellence, we needed to ensure our teams were conducting exploratory disaster scenario testing to know for certain how our apps/service behaved and improve our Dev Ops code, monitoring/alerting, runbooks, etc. Documenting the procedures was completed in the late summer. That quickly moved into evaluating our assumptions and correcting where necessary.
All teams were responsible for:
documentation the test plan
documentation of the results
capture the MTTR (mean time to recovery) when appropriate
Sign off was required for all test plans and results shared amongst the teams. We also executed a full set of Disaster Recovery scenarios and performed additional Green Flag fire drills to ensure all systems and personnel were prepared for any contingencies during the holiday season.
Load/Performance Testing
For an added layer of insurance, we pre scaled our environment ahead of the anticipated holiday load profile. Analysis of 3 years of previous holiday traffic showed a predictable increase of approximately 2.5x the highest load average over the past 10 months. For this holiday season we tested at 4x the highest load average over that time period to ensure we were covered. The load test allowed the team to test beyond expected target traffic profile to ensure all systems would execute above expected levels.
Load testing initially was isolated per each system. Conducting tests in such environment helped quickly identify any failure points. As satisfactory results were obtain, complexities were introduced by running systems in tandem. This simulated a environments more representative of what would be encountered in the holiday season.
One benefit experienced through this testing was the identification and evaluation of other key metrics to ensure the systems are operating and performing successfully. Also, a predictive model was created to evaluate our expected results. The accuracy of the daily model was within 5% of the expected daily results and overall, for the 2015 season, was within 3%. This new model will be a essential tool when preparing for the next holiday season.
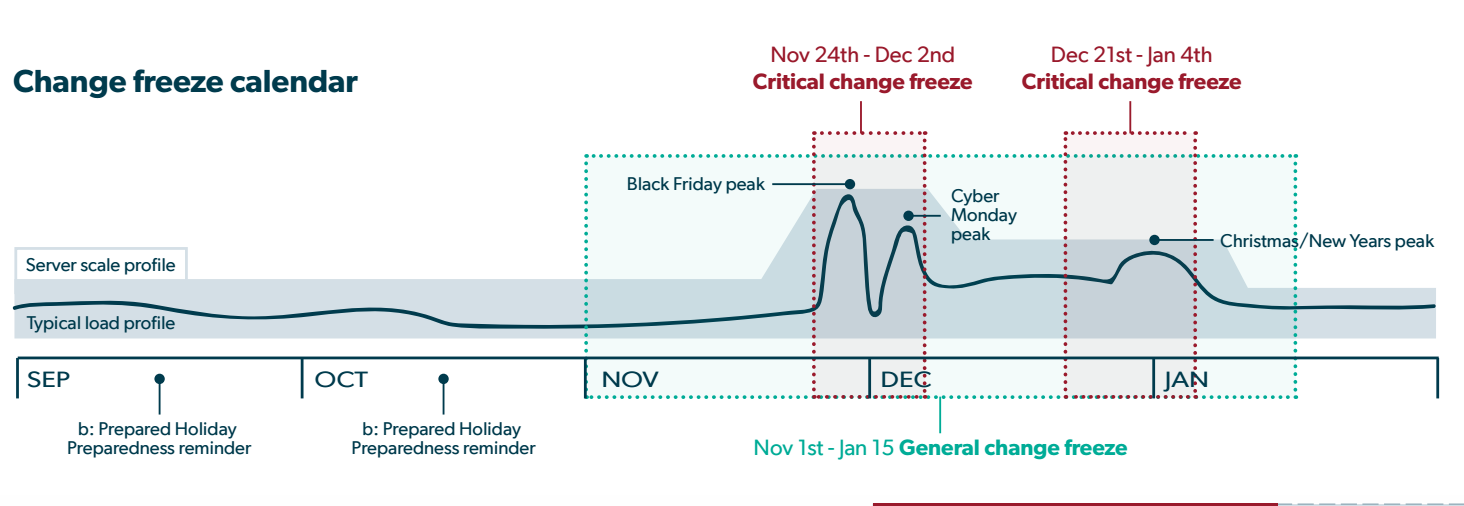
Freeze Plan
Once again, we locked down the code prior to the holiday season. Limiting the number of ‘moving parts’ and throughly testing the code in place increased our confidence that we would not experience any major issues. As the image below demonstrates, two critical time periods were identified:
critical change freeze – code change to be introduced only if sites were down.
general change freeze – priority one bug fixes were accepted. Additional risk assessments performed on all changes.
As you can see the critical times coincide with the times we see increased online traffic.
Summary
A substantial amount of the work was all completed in the months prior to Black Friday and Cyber Monday. The team’s coordinated efforts prior to the holiday season ensured that our client’s online operations ran smoothly. Over half of the year was spent ensuring performance and scalability for these critical times in the holiday season. Data, as far back as three years, was also used to predict web traffic forecasts and ensure we would scale appropriately. This metric perspective also provided new insightful models to be used in future year’s forecasts.
The preparation paid off, and Bazaarvoice was able to handle 8.398 Billion impressions over Black Friday thru Cyber Monday (11/27-11/30), a new record for the our network.
Every year Bazaarvoice R&D throws BVIO, an internal technical conference followed by a two-day hackathon. These conferences are an opportunity for us to focus on unlocking the power of our network, data, APIs, and platforms as well as have some fun in the process. We invite keynote speakers from within BV, from companies who use our data in inspiring ways, and from companies who are successfully using big data to solve cool problems. After a full day of learning we engage in an intense, two-day hackathon to create new applications, visualizations, and insights into our extensive our data.
Continue reading for pictures of the event and videos of the presentations.
This year we held the conference at the palatial Omni Barton Creek Resort in one of their well-appointed ballrooms.
Participants arrived around 9am (some of us a little later). After breakfast, provided by Bazaarvoice, we got started with the speakers followed by lunch, also provided by Bazaarvoice, followed by more speakers.
After the speakers came a “pitchfest” during which our Product team presented hackathon ideas and participants started forming teams and brainstorming.
Finally it was time for 48 hours of hacking, eating, and gaming (not necessarily in that order) culminating in project presentations and prizes.
Presentations
Sephora: Consumer Targeted Content
Venkat Gopalan
Director of Architecture & Devops @ Sephora.com
Venkat presented on the work Sephora is doing around serving relevant, targeted content to their consumers in both the mobile and in-store space. It was a fascinating speech and we love to see our how our clients are innovating with us. Unfortunately due to technical difficulties we don’t have a recording 🙁
Philosophy & Design of The BV System of Record
John Roesler & Fahd Siddiqui
Bazaarvoice Engineers
This talk was about the overarching design of Bazaarvoice’s innovative data architecture. According to them there are aspects to it that may seem unexpected at first glance (especially not coming from a big data background), but are actually surprisingly powerful. The first innovation is the separation of storage and query, and the second is choosing a knowledge-base-inspired data model. By making these two choices, we guarantee that our data infrastructure will be robust and durable.
Realtime Bidding: Predicting the future, 10,000 times per second
Ian has built and manages a team of world-class software engineers as well as data scientists at OneSpot™s. In his presentation he discusses how he applied machine learning and game theory to architect a sophisticated realtime bidding engine for OneSpot™ capable of predicting the behavior of tens of thousands of people per second.
New Amazon Machine Learning and Lambda architectures
In his presentation Jeff discusses the history of Amazon Machine Learning and the Lambda architecture, how Amazon uses it and you can use it. This isn’t just a presentation; Ian walks us through the AWS UI for building and training a model.
Thanks to Sharon Hasting, Dan Heberden, and the presenters for contributing to this post.
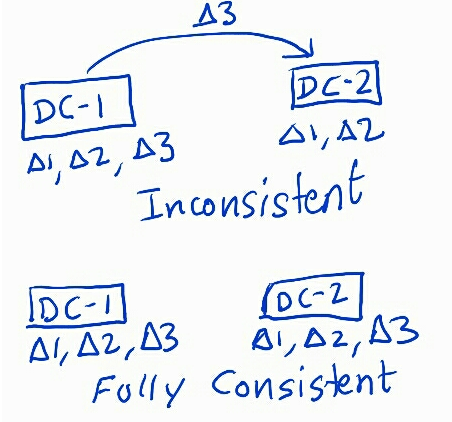
A distributed data system consisting of several nodes is said to be fully consistent when all nodes have the same state of the data they own. So, if record A is in State S on one node, then we know that it is in the same state in all its replicas and data centers.
Full Consistency sounds great. The catch is the CAP theorem that states that its impossible for a distributed system to simultaneously guarantee consistency (C), availability (A), and partition tolerance (P). At Bazaarvoice, we have sacrificed full consistency to get an AP system and contend with an eventually consistent data store. One way to define eventual consistency is that there is a point in time in the past before which the system is fully consistent (full consistency timestamp, or FCT). The duration between FCT and now is called the Full Consistency Lag (FCL).
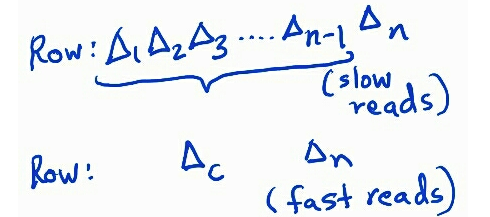
An eventually consistent system may never be in a fully consistent state given a massive write throughput. However, what we really want to know deterministically is the last time before which we can be assured that all updates were fully consistent on all nodes. So, in the figure above, in the inconsistent state, we would like to know that everything up to Δ2 has been replicated fully, and is fully consistent. Before we get down to the nitty-gritty of this metric, I would like to take a detour to set up the context of why it is so important for us to know the full consistency lag of our distributed system.
At Bazaarvoice, we employ an eventually consistent system of record that is designed to span multiple data centers, using multi-master conflict resolution. It relies on Apache Cassandra for persistence and cross-data-center replication.
One of the salient properties of our system of record is immutable updates. That essentially means that a row in our data store is simply a sequence of immutable updates, or deltas. A delta can be a creation of a new document, an addition, modification, or removal of a property on the document, or even a deletion of the entire document. For example, a document is stored in the following manner in Cassandra, where each delta is a column of the row.
Note that these deltas are stored as key-value pairs with the key as Time UUID. Cassandra would thus always present them in increasing order of insertion, making sure the last-write-wins property. Storing the rows in this manner allows us massive non-blocking global writes. Writes to the same row from different data centers across the globe would eventually achieve a consistent state without making any cross-data center calls. This point alone warrants a separate blog post, but it will have to suffice for now.
To recap, rows are nothing but a sequence of deltas. Writers simply append these deltas to the row, without caring about the existing state of the row. When a row is read, these deltas are resolved in ascending order and produce a json document.
There is one problem with this: over time rows will accrue a lot of updates causing the row to become really wide. The writes will still be OK, but the reads can become too slow as the system tries to consolidate all those deltas into one document. This is where compaction helps. As the name suggests, compaction resolves several deltas, and replaces them with one “compacted” delta. Any subsequent reads will only see a compaction record, and the read slowness issue is resolved.
Great. However, there is a major challenge that comes with compaction in a multi-datacenter cluster. When is it ok to compact rows on a local node in a data center? Specifically, what if an older delta arrives after we are done compacting? If we arbitrarily decide to compact rows every five minutes, then we run the risk of losing deltas that may be in flight from a different data center.
To solve this issue, we need to figure out what deltas are fully consistent on all nodes and only compact those deltas, which basically is to say, “Find time (t) in the past, before which all deltas are available on all nodes”. This t, or full consistency timestamp, assures us that no deltas will ever arrive with a time UUID before this timestamp. Thus, everything before the full consistency timestamp can be compacted without any fear of data loss.
There is just one issue. This metric is absent in out of the box AP systems such as Cassandra. To me, this is a vital metric for an AP system. It would be rare to find a business use case in which permanent inconsistency is tolerable.
Although Cassandra doesn’t provide the full consistency lag, we can still compute it in the following way:
Tf = Time no hints were found on any node
rpc_timeout = Maximum timeout in cassandra that nodes will use when communicating with each other.
FCT = Full Consistency Timestamp
FCL = Full Consistency Lag
FCT = Tf – rpc_timeout
FCL = Tnow – FCT
The concept of Hinted Handoffs was introduced in Amazon’s dynamo paper as a way of handling failure. This is what Cassandra leverages for fault-tolerant replication. Basically, if a write is made to a replica node that is down, then Cassandra will write a “hint” to the coordinator node and try again in a configured amount of time.
We exploit this feature of Cassandra to get us our full consistency lag. The main idea is to poll all the nodes to see if they have any pending hints for other nodes. The time when they all report zero (Tf) is when we know that there are no failed writes, and the only pending writes are those that are in flight. So, subtracting the cassandra timeout (rpc_timeout) will give us our full consistency lag.
Now, that we have our full consistency lag, this metric can be used to alert the appropriate people when the cluster is lagging too far behind.
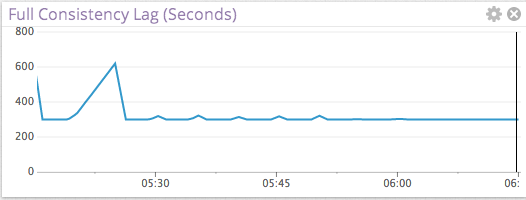
Finally, you would want to graph this metric for monitoring.
Note that in the above graph we artificially added a 5 minute lag to our rpc_timeout value to avoid excessively frequent compactions. We periodically poll for full consistency every 300 seconds (or 5 minutes). You should tweak this value according to your needs. For our settings above, the expected lag is 5 minutes, but you can see it spike at 10 minutes. All that really says is there was one time when we checked and found a few hints. The next time we checked (after 5 minutes in our case) all hints were taken care of. You can now set an alert in your system that should wake people up if this lag violates a given threshold–perhaps several hours–something that makes sense for your business.
Every holiday season, the virtual doors of your favorite retailer are blown open by a torrent of shoppers who are eager to find the best deal, whether they’re looking for a Turbo Man action figure or a ludicrously discounted 4K flat screen. This series focuses on our Big Data analytics platform, which is used to learn more about how people interact with our network.
The challenge
Within the Reporting & Analytics group, we use Big Data analytics to help some of the world’s largest brands and retailers understand how to most effectively serve their customers, as well as provide those customers with the information they need to make informed buying decisions. The amount of clickstream traffic we see during the holidays – over 45,000 events per second, produced by 500 million monthly unique visitors from around the world – is tremendous.
In fact, if we reserved a seat at the Louisiana Superdome for each collected analytics event, we would fill it up in about 1.67 seconds. And, if we wanted to give each of our monthly visitors their own seat in a classic Beetle, we’d need about 4.64 times the total number produced between 1938 and 2003. That’s somewhere in the neighborhood of a hundred million cars!
Fortunately for us, we live in the era of Big Data and high scalability. Our platform, which is based on the principles outlined in Nathan Marz’s Lambda architecture design, addresses the requirements of ad-hoc, near real-time, and batch applications. Before we could analyze any data, however, we needed a way to reliably collect it. That’s where our in-house event collection service, which we named “Cookie Monster,” came into the picture.
Collecting the data
When investigating how clients would send events to us, our engineers knew that the payload had to fit within the query string of an HTTP GET request. They settled upon a lightweight serialization format called Rison, which expresses JSON data structures, but is designed to support URI encoding semantics. (Our Rison plugin for Jackson, which we leverage to handle the processing of Rison-encoded events, is available on GitHub.)
In addition, we decided to implement support for client-side batching logic, which would allow a web browser to send multiple events within the payload of a single request. By sending fewer requests, we reduced the amount of HTTP transaction overhead, which minimized the amount of infrastructure required to support a massive network audience. Meanwhile, as their browsers would only need to send one request, end-users also saw a performance uptick.
Because the service itself needed a strong foundation, we chose the ubiquitous Dropwizard framework, which accelerated development by providing the basic ingredients needed to create a maintainable, scalable, and performant web service. Dropwizard glues together Jetty (a high-performance web server), Jersey (a framework for REST-ful web services), and Jackson (a JSON processor).
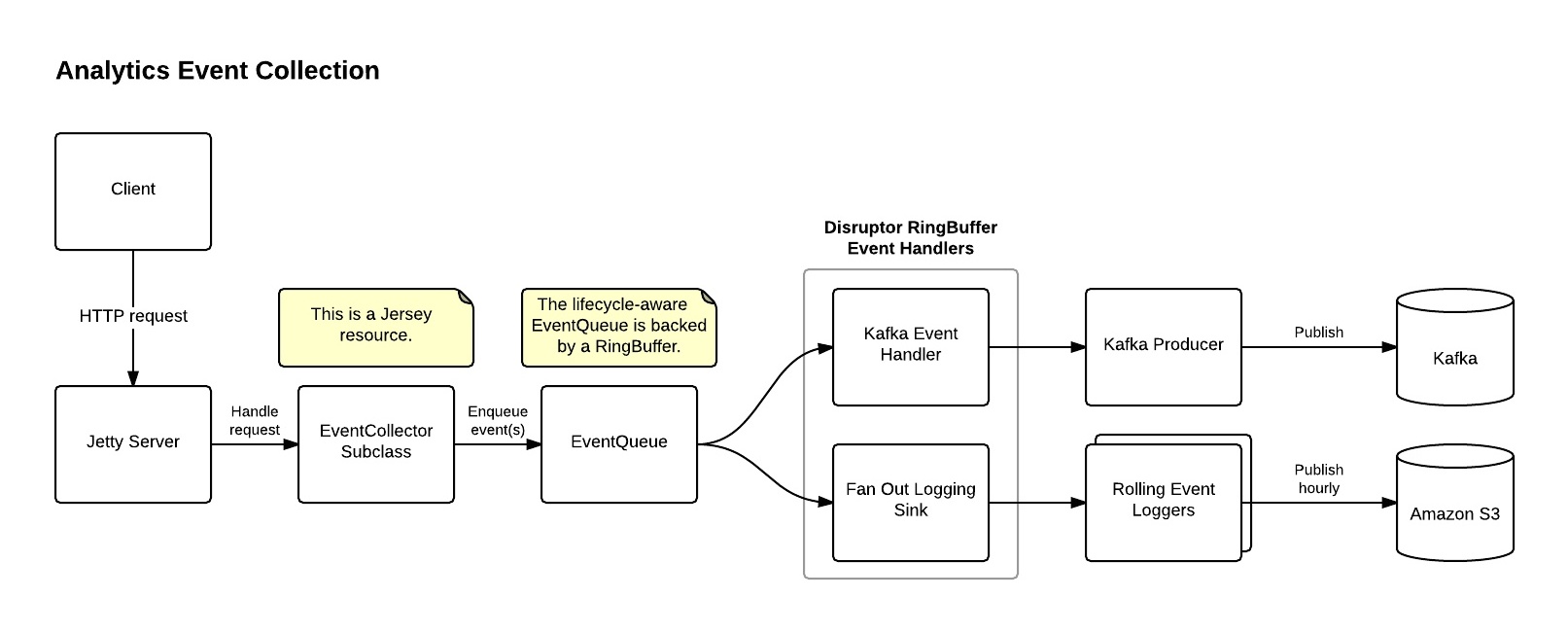
Perhaps most importantly, we used the Disruptor library‘s ring buffer implementation to facilitate very fast inter-thread messaging. When a new event arrives, it is submitted to the EventQueue by the EventCollector. Two event handler classes, which listen for ring events, ensure that the event is delivered properly. The first event handler acts as a producer for Kafka, publishing the event to the appropriate topic. (Part two of this series will discuss Kafka in further detail.)
The second is a “fan out” logging sink, which mods specific event metadata and delivers the corresponding event to the appropriate logger. At the top of every hour, the previous hour’s batch logs are delivered to S3, and then consumed by downstream processes.
In the real world
When building Cookie Monster, we knew that our service would need to maintain as little state as possible, and accommodate the volatility of cloud infrastructure.
Because EC2 is built on low-cost, commodity hardware, we knew that we couldn’t “cheat” with sophisticated hardware RAID – everything would run on machines that were naturally prone to failure. In our case, we deemed those trade-offs acceptable, as our design goals for a distributed system aligned perfectly with the intent of EC2 auto-scaling groups.
Even though the service was designed for EC2, there were a few hiccups along the way, and we’ve learned many valuable lessons. For example, the Elastic Load Balancer, which distributes HTTP requests to instances within the Auto Scaling group, must be “pre-warmed” before accepting a large volume of traffic. Although that’s by design, it means that good communication with AWS prior to deployment must be a crucial part of our process.
Also, Cookie Monster was designed prior to the availability of EBS optimized instances and provisioned IOPS, which allow for more consistent performance of an I/O-bound process when using EBS volumes. Even in today’s world, where both of those features could be enabled, ephemeral (i.e. host-local) volumes remain a fiscally compelling – if brittle – alternative for transient storage. (AWS generally discourages the use of ephemeral storage where data loss is a concern, as they are prone to failure.)
Ultimately, our choice to deploy into EC2 paid off, and it allowed us to scale the service to stratospheric heights without a dedicated operations team. Today, Cookie Monster remains an integral service within our Big Data analytics platform, successfully collecting and delivering many billions of events from all around the world.