
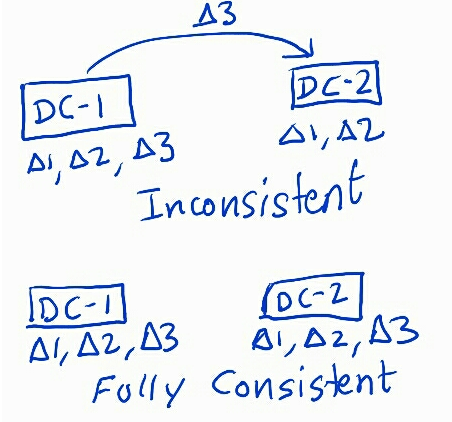
A distributed data system consisting of several nodes is said to be fully consistent when all nodes have the same state of the data they own. So, if record A is in State S on one node, then we know that it is in the same state in all its replicas and data centers.
Full Consistency sounds great. The catch is the CAP theorem that states that its impossible for a distributed system to simultaneously guarantee consistency (C), availability (A), and partition tolerance (P). At Bazaarvoice, we have sacrificed full consistency to get an AP system and contend with an eventually consistent data store. One way to define eventual consistency is that there is a point in time in the past before which the system is fully consistent (full consistency timestamp, or FCT). The duration between FCT and now is called the Full Consistency Lag (FCL).
An eventually consistent system may never be in a fully consistent state given a massive write throughput. However, what we really want to know deterministically is the last time before which we can be assured that all updates were fully consistent on all nodes. So, in the figure above, in the inconsistent state, we would like to know that everything up to Δ2 has been replicated fully, and is fully consistent. Before we get down to the nitty-gritty of this metric, I would like to take a detour to set up the context of why it is so important for us to know the full consistency lag of our distributed system.
At Bazaarvoice, we employ an eventually consistent system of record that is designed to span multiple data centers, using multi-master conflict resolution. It relies on Apache Cassandra for persistence and cross-data-center replication.
One of the salient properties of our system of record is immutable updates. That essentially means that a row in our data store is simply a sequence of immutable updates, or deltas. A delta can be a creation of a new document, an addition, modification, or removal of a property on the document, or even a deletion of the entire document. For example, a document is stored in the following manner in Cassandra, where each delta is a column of the row.
Δ1 { “rating”: 4,
“text”: “I like it.”}
Δ2 { .., “status”: “APPROVED” }
Δ3 { .., “client”: “Walmart” }
So, when a document is requested, the reader process resolves all the above deltas (Δ1 + Δ2 + Δ3) in that order, and produces the following document:
{ “rating”: 4,
“text”: “I like it.”,
“status”: “APPROVED”,
“client”: “Walmart”,
“~version”: 3 }
Note that these deltas are stored as key-value pairs with the key as Time UUID. Cassandra would thus always present them in increasing order of insertion, making sure the last-write-wins property. Storing the rows in this manner allows us massive non-blocking global writes. Writes to the same row from different data centers across the globe would eventually achieve a consistent state without making any cross-data center calls. This point alone warrants a separate blog post, but it will have to suffice for now.
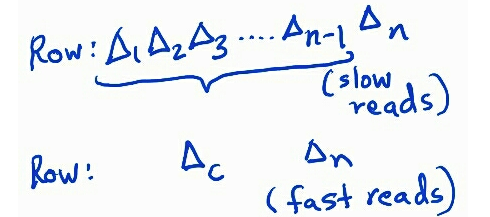
To recap, rows are nothing but a sequence of deltas. Writers simply append these deltas to the row, without caring about the existing state of the row. When a row is read, these deltas are resolved in ascending order and produce a json document.
There is one problem with this: over time rows will accrue a lot of updates causing the row to become really wide. The writes will still be OK, but the reads can become too slow as the system tries to consolidate all those deltas into one document. This is where compaction helps. As the name suggests, compaction resolves several deltas, and replaces them with one “compacted” delta. Any subsequent reads will only see a compaction record, and the read slowness issue is resolved.
Great. However, there is a major challenge that comes with compaction in a multi-datacenter cluster. When is it ok to compact rows on a local node in a data center? Specifically, what if an older delta arrives after we are done compacting? If we arbitrarily decide to compact rows every five minutes, then we run the risk of losing deltas that may be in flight from a different data center.
To solve this issue, we need to figure out what deltas are fully consistent on all nodes and only compact those deltas, which basically is to say, “Find time (t) in the past, before which all deltas are available on all nodes”. This t, or full consistency timestamp, assures us that no deltas will ever arrive with a time UUID before this timestamp. Thus, everything before the full consistency timestamp can be compacted without any fear of data loss.
There is just one issue. This metric is absent in out of the box AP systems such as Cassandra. To me, this is a vital metric for an AP system. It would be rare to find a business use case in which permanent inconsistency is tolerable.
Although Cassandra doesn’t provide the full consistency lag, we can still compute it in the following way:
Tf = Time no hints were found on any node
rpc_timeout = Maximum timeout in cassandra that nodes will use when communicating with each other.
FCT = Full Consistency Timestamp
FCL = Full Consistency Lag
FCT = Tf – rpc_timeout
FCL = Tnow – FCT
The concept of Hinted Handoffs was introduced in Amazon’s dynamo paper as a way of handling failure. This is what Cassandra leverages for fault-tolerant replication. Basically, if a write is made to a replica node that is down, then Cassandra will write a “hint” to the coordinator node and try again in a configured amount of time.
We exploit this feature of Cassandra to get us our full consistency lag. The main idea is to poll all the nodes to see if they have any pending hints for other nodes. The time when they all report zero (Tf) is when we know that there are no failed writes, and the only pending writes are those that are in flight. So, subtracting the cassandra timeout (rpc_timeout) will give us our full consistency lag.
Now, that we have our full consistency lag, this metric can be used to alert the appropriate people when the cluster is lagging too far behind.
Finally, you would want to graph this metric for monitoring.
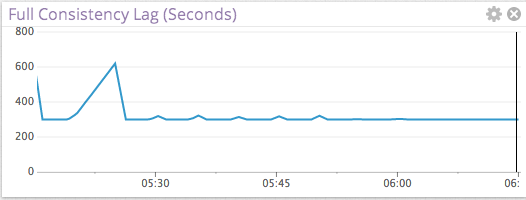
Note that in the above graph we artificially added a 5 minute lag to our rpc_timeout value to avoid excessively frequent compactions. We periodically poll for full consistency every 300 seconds (or 5 minutes). You should tweak this value according to your needs. For our settings above, the expected lag is 5 minutes, but you can see it spike at 10 minutes. All that really says is there was one time when we checked and found a few hints. The next time we checked (after 5 minutes in our case) all hints were taken care of. You can now set an alert in your system that should wake people up if this lag violates a given threshold–perhaps several hours–something that makes sense for your business.