
Every holiday season, the virtual doors of your favorite retailer are blown open by a torrent of shoppers who are eager to find the best deal, whether they’re looking for a Turbo Man action figure or a ludicrously discounted 4K flat screen. This series focuses on our Big Data analytics platform, which is used to learn more about how people interact with our network.
The challenge
Within the Reporting & Analytics group, we use Big Data analytics to help some of the world’s largest brands and retailers understand how to most effectively serve their customers, as well as provide those customers with the information they need to make informed buying decisions. The amount of clickstream traffic we see during the holidays – over 45,000 events per second, produced by 500 million monthly unique visitors from around the world – is tremendous.
In fact, if we reserved a seat at the Louisiana Superdome for each collected analytics event, we would fill it up in about 1.67 seconds. And, if we wanted to give each of our monthly visitors their own seat in a classic Beetle, we’d need about 4.64 times the total number produced between 1938 and 2003. That’s somewhere in the neighborhood of a hundred million cars!
Fortunately for us, we live in the era of Big Data and high scalability. Our platform, which is based on the principles outlined in Nathan Marz’s Lambda architecture design, addresses the requirements of ad-hoc, near real-time, and batch applications. Before we could analyze any data, however, we needed a way to reliably collect it. That’s where our in-house event collection service, which we named “Cookie Monster,” came into the picture.
Collecting the data
When investigating how clients would send events to us, our engineers knew that the payload had to fit within the query string of an HTTP GET request. They settled upon a lightweight serialization format called Rison, which expresses JSON data structures, but is designed to support URI encoding semantics. (Our Rison plugin for Jackson, which we leverage to handle the processing of Rison-encoded events, is available on GitHub.)
In addition, we decided to implement support for client-side batching logic, which would allow a web browser to send multiple events within the payload of a single request. By sending fewer requests, we reduced the amount of HTTP transaction overhead, which minimized the amount of infrastructure required to support a massive network audience. Meanwhile, as their browsers would only need to send one request, end-users also saw a performance uptick.
Because the service itself needed a strong foundation, we chose the ubiquitous Dropwizard framework, which accelerated development by providing the basic ingredients needed to create a maintainable, scalable, and performant web service. Dropwizard glues together Jetty (a high-performance web server), Jersey (a framework for REST-ful web services), and Jackson (a JSON processor).
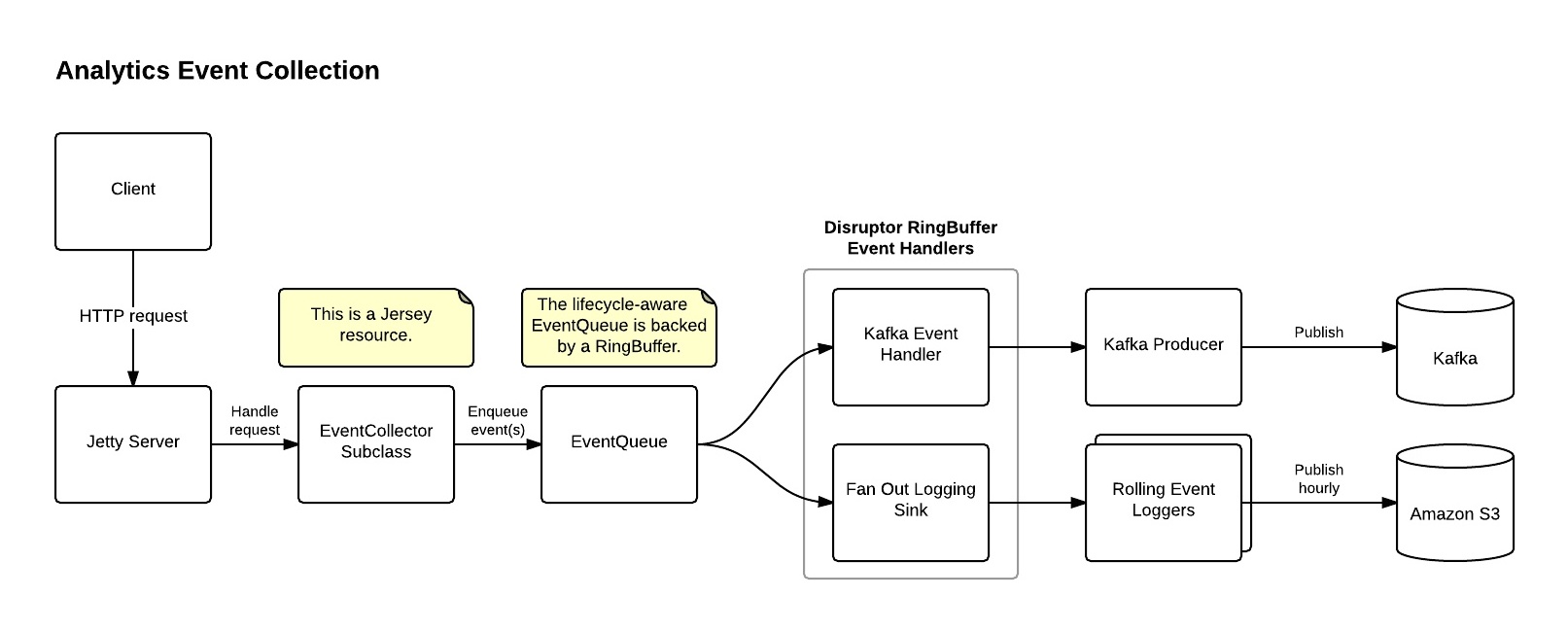
Perhaps most importantly, we used the Disruptor library‘s ring buffer implementation to facilitate very fast inter-thread messaging. When a new event arrives, it is submitted to the EventQueue by the EventCollector. Two event handler classes, which listen for ring events, ensure that the event is delivered properly. The first event handler acts as a producer for Kafka, publishing the event to the appropriate topic. (Part two of this series will discuss Kafka in further detail.)
The second is a “fan out” logging sink, which mods specific event metadata and delivers the corresponding event to the appropriate logger. At the top of every hour, the previous hour’s batch logs are delivered to S3, and then consumed by downstream processes.
In the real world
When building Cookie Monster, we knew that our service would need to maintain as little state as possible, and accommodate the volatility of cloud infrastructure.
Because EC2 is built on low-cost, commodity hardware, we knew that we couldn’t “cheat” with sophisticated hardware RAID – everything would run on machines that were naturally prone to failure. In our case, we deemed those trade-offs acceptable, as our design goals for a distributed system aligned perfectly with the intent of EC2 auto-scaling groups.
Even though the service was designed for EC2, there were a few hiccups along the way, and we’ve learned many valuable lessons. For example, the Elastic Load Balancer, which distributes HTTP requests to instances within the Auto Scaling group, must be “pre-warmed” before accepting a large volume of traffic. Although that’s by design, it means that good communication with AWS prior to deployment must be a crucial part of our process.
Also, Cookie Monster was designed prior to the availability of EBS optimized instances and provisioned IOPS, which allow for more consistent performance of an I/O-bound process when using EBS volumes. Even in today’s world, where both of those features could be enabled, ephemeral (i.e. host-local) volumes remain a fiscally compelling – if brittle – alternative for transient storage. (AWS generally discourages the use of ephemeral storage where data loss is a concern, as they are prone to failure.)
Ultimately, our choice to deploy into EC2 paid off, and it allowed us to scale the service to stratospheric heights without a dedicated operations team. Today, Cookie Monster remains an integral service within our Big Data analytics platform, successfully collecting and delivering many billions of events from all around the world.