Greetings all! In the world of SaaS, wiser men than I have referred to Operations as the “Secret Sauce” that distinguishes you from your competition. As manager of one of our DevOps teams, I wanted to talk to you about how Bazaarvoice uses the cloud and how we engineer our systems for maximum reliability.
You may have heard about the AWS Storm and the Leapocalypse, two events that made the weekend of June 29th last year a sad one for many Internet companies. Electrical storms in the Northeast knocked out one of Amazon Web Service’s availability zones in their US East region Friday night, knocking many services off the air (Netflix, Mozilla, Pinterest, Heroku, LinkedIn, Foursquare, Yelp, Instagram, Reddit, and many more). Then on Saturday a “leap second” caused Java virtual machines across the planet to freak out and peg CPUs. Guess what two technologies we use heavily here at Bazaarvoice? That’s right, Amazon Web Services and Java.
Here’s a great graph from alerting service PagerDuty showing the impact these two events had across the Internet:
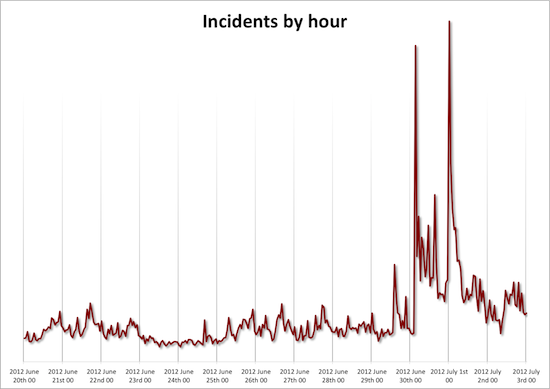
But here’s the Keynote graph we use to continually monitor our customer facing services for the same time period:
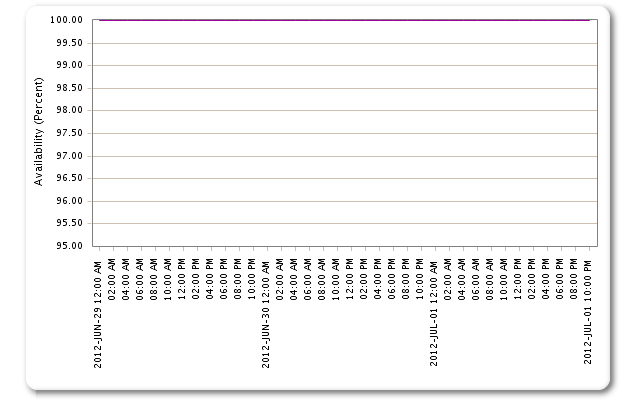
It’s really five different graphs for a set of our major customers overlaid, but it’s hard to tell because they are all flatlined on top of each other. That’s right – we had 100% availability on all our properties for the entire crisis period.
Were we “untouched?” By no means. We lost 77 servers, 37 of which were production servers, during this time. But by architecting for resilience, we have constructed a system to avoid customer impact even when an outage hits our systems like a shotgun blast.
As you know from previous blog posts, we’re a big Solr and mySQL shop. We shard our customers into distinct “clusters” for scalability (we’re up to seven). But then each cluster is mirrored into the AWS East region, AWS West region, and Rackspace. Inside each region, we make use of multiple availability zones and levels of load balancing (haproxy in the cloud, F5 in Rackspace). Here’s the view inside one region (1/3 of a cluster):
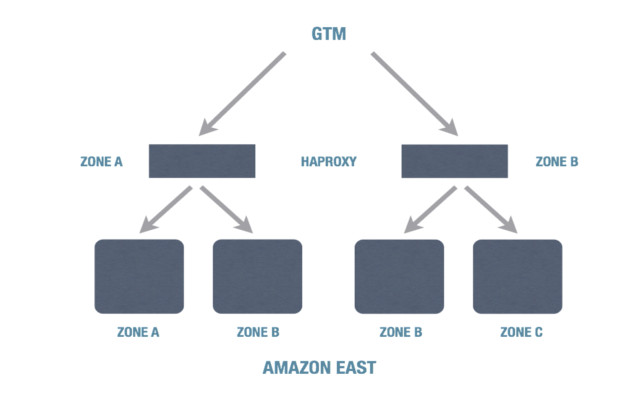
Then we use Neustar GTM for DNS-based traffic balancing across all three parts of the cluster in AWS East, AWS West, and Rackspace. This means we can lose zones within a region, or even a full region, without downtime – though in a case like this, we definitely had to expand our capacity in AWS West when AWS East went down so that we wouldn’t have performance issues, and we did have engineers working over the weekend to clean up the “debris” left over from the outage. We are working on engineering our clusters to dynamically scale up and clean up behind themselves to avoid that manual work.
But what about the data, you ask? Well, the other key to this setup is that we use a message queue for all writes instead of writing synchronously to the database. This gives us a huge amount of flexibility in how and where we process them – we use a master/slave relationship for each cluster where the mySQL and Solr are mastered out of Rackspace, but with that architecture if Rackspace were completely down all that does is delay content submission – nothing is lost and the user experience is still good.
This architecture also allows us to scale quickly and gives us a lot of control over shifting traffic around to meet specific challenges (like Black Friday). More on that in a later post, but I hope this gives you some insight into how we make our service as reliable as we can!
