A while ago, I published a post on this blog about how to perform retrospectives for development teams who proscribe to Kanban and/or the agile development process.
You can read that post here: Don’t Look Back in Anger
I’ve received a lot of feedback on that blog post – enough that I thought I’d follow up with an additional post that details further fine-tuning of our retrospective process – a retro of retros if you will but first…
 Yo dawg, I heard you like old memes...
Yo dawg, I heard you like old memes...
OK, now with that out of the way – here’s some insights into what we’ve learned from looking back at the retrospectives we’ve performed over time:
It’s Not Just for Development Teams
Regardless whether you’re using Kanban, Agile development, other forms of SDLC management, (insert snazzy development jargon buzzword here) or not – the process of re-evaluation and improvement can be applied to any team process.
After the previous blog post was published, I had a member of our product knowledge team approach me to tell me how they were planning on using the retrospective process to improve how they communicate technical details to our clients.
It seems like an obvious move but honestly, as the retro process laid out in the previous blog post was very specific to the agile/Kanban management process, I felt this was worth mentioning here.
You Need Moderation
This was only briefly mentioned in the previous blog post but, as we’ve conducted further retrospectives, it became clear that some form of moderation during the retrospective sessions was needed.
In this case, I’m not talking about the need for a designee to “take the minutes” of your sessions (you should already be doing this) but we found that the team really needed someone to help move the retrospective along. Here’s why:
Time is an Expense – Yup, time is money and if you have a large team spending a large amount of time in retrospective, somewhere, someone is thinking – “boy, that’s a lot of billable hours going on in that meeting”. You need a moderator to help stick to the time box you’ve put together for your retrospective. Spend the necessary time for review but not too much time.
Technical Teams go Down Technical Rabbit Holes – And that’s because, especially if you’re dealing with highly technical teams, we by default are pretty obsessed with solving complex problems. You get enough engineers together to discuss how to solve for there being 4 different competing programming frameworks and you’re going to end up with 5 competing frameworks. Focus on technical solutions is necessary to solving problems but it’s good to have someone keep the team focused on identifying problems here; determining technical feasibility should be done outside the retrospective.
 This really does happens - that's why its funny
This really does happens - that's why its funny
Emotional Teams go Down Emotional Rabbit Holes (and all teams are emotional) – Technical prowess aside, people are people and we tend to have some pretty strong feelings about things, one way or another. If you don’t skirt the danger of falling into a technical time sink of a discussion, I guarantee you that you will at some point fall into an emotionally charged one. It’s important to have someone help the team keep the discussion tight and focused – so we can focus our passions on moving forward (after we cleared some of the path forward in your retrospective).

How Do You Moderate?
This has been the subject of many, many management books, articles and college thesis papers. There’s way too much to unpack when it comes to how to moderate your team meetings (hint, it depends on your team) but here’s some hints we’ve picked up along the way:
Time Can’t Change Me – Don’t be afraid to use a timer (you all have smart phones and there’s an app for that)! If you’re following a format similar to the one outlined in the previous post – each subsequent phase tends to take longer than the previous one – allocate time accordingly.
Simple Division – Since you’ve likely divided your retro into phases and slated a time limit to conduct it in, divide your time slated for the retrospective among those phases.
Keep in mind the number of people on your time – try to sub-divide time allocated for each phase for each team member (e.g. five members and 15 minutes for phase one? – Try to keep everyone close to 3 minutes a piece per phase).
The Kindest Cut – Don’t be afraid to cut someone off if it looks like their starting to dominate the conversation (but do this gently and with tact).
Take notes of heated discussion points (particularly if it’s between a small subset of your team). Promise to follow up with those team members with a further discussion of their points – which are important, but do focus on keeping the meeting moving forward.
Remind the team that the sooner the meeting concludes the sooner everyone can get back to work as a team (that’s the whole goal here anyway).
Take Notes:
Again, this was briefly touched upon in the previous post. Initially, when we began the retrospective process, we weren’t very diligent on taking notes aside from noting which to-do items we wanted to take away and work toward after each retrospective.
The further we refined our process however, to more detailed notes we not only kept but also published.
Taking notes was key to us further refining our process because two things became apparent when looking back at our notes from our previous retrospectives:
- Some of our to-dos, while we committed time and effort to improve, were brought up again in later retrospectives.
- Some of our pressing needs at the time of a specific retrospective became non-issues as our team naturally evolved.
Capturing the former allowed us to recognize a persistent problem the team identified but required consecutive effort to resolve. In this case, we appeared to keep taking on more work within our Kanban process than we had bandwidth to resolve (biting off more than we could chew). This moment of realization resulted in becoming the central topic of its own retrospective.
The latter, while on the outset seemed not necessarily noteworthy, did provide an ah-ha moment for the team when we could see in black-and-white, on our Confluence page, evidence of not only of our team evolving but in one way or another, improving.
Anonymity Can Be Powerful:
People are people and aside from that being a Depeche Mode song we found that people frankly sometimes don’t like to be put on the spot. In this case, when we conducted our retrospective retrospective (see the whole thing about the combo breaker below), feedback from several team members spoke about the round-robin style forum method of team discussing highlighted in the our initial blog post.
The main criticism was that, while that method of discussion did help the team to consensually highlight both what went well and what could be improved, the act of doing so in this manner made some people uncomfortable.
The item for improvement became how we can better facilitate our already established method of feedback – while reducing some of the personal, individual aspects of the process to make some team members more comfortable (again, people are people, people are different, some approach different forms of interaction better than others and if you plan on working together as a functional team, that is a fact you will need to address).
 The other half consists of porkchop sandwiches
The other half consists of porkchop sandwiches
Our solution took inspiration for our company happy hour and team building invites (no seriously, I was not writing this while racing go karts or having margaritas with the team).

We simply decided to move a portion of our team discussing to a service like Survey Monkey:
- We would put forth a discussion topic session for our future retrospective sessions
- Invite team members to “the party”
- Allowed anonymous submissions to the survey (suggestions for the upcoming “party”)
- Allowed voting for submitted topics for both well-done and to-improve points of discussion
- Collected the anonymous submissions, focusing on substantially up-voted items
- And brought those to the retrospective meeting
 These cacti rock
These cacti rock
Not only did this give some people a more relaxed avenue to provide feedback, it also cut down on the time needed for performing the actual retrospective meeting (a big plus if you’re dealing with a large team).
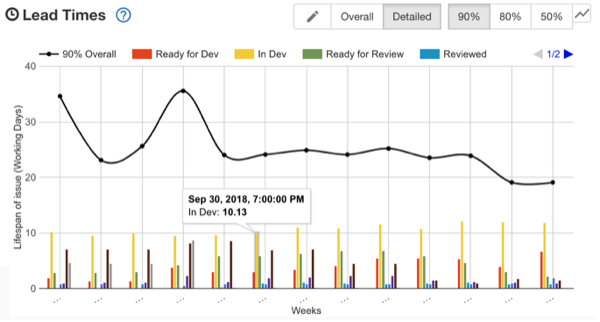
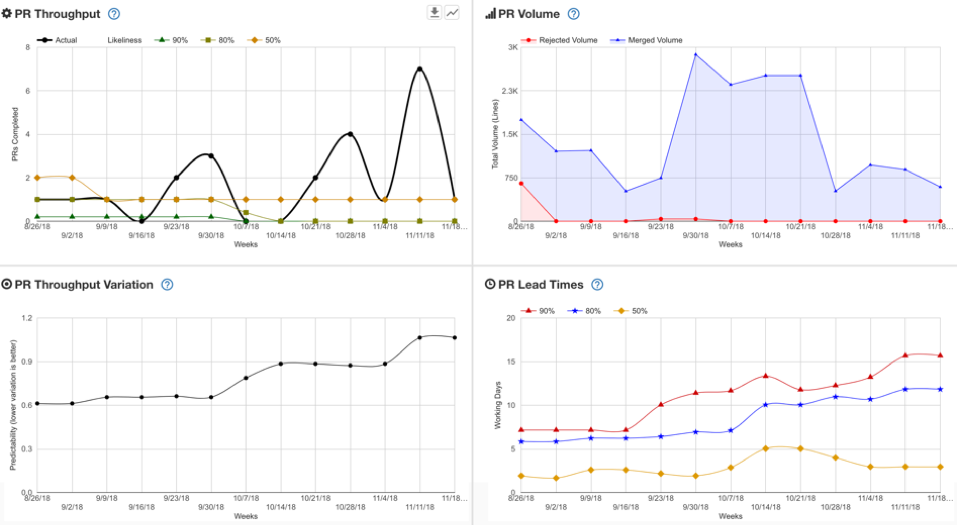
Get Metrics Involved:
Applying data science to your own development work itself can be its own full-time job especially if you’re working with a large team or multiple teams.
Now you’re probably thinking, “Oh man, don’t tell me to get all crazy with standard deviations and bell-curves for our own retrospectives – this isn’t a performance review!”
And you’re right – but hear me out. It pays to have some metrics available when you conduct a retro. Story Time!
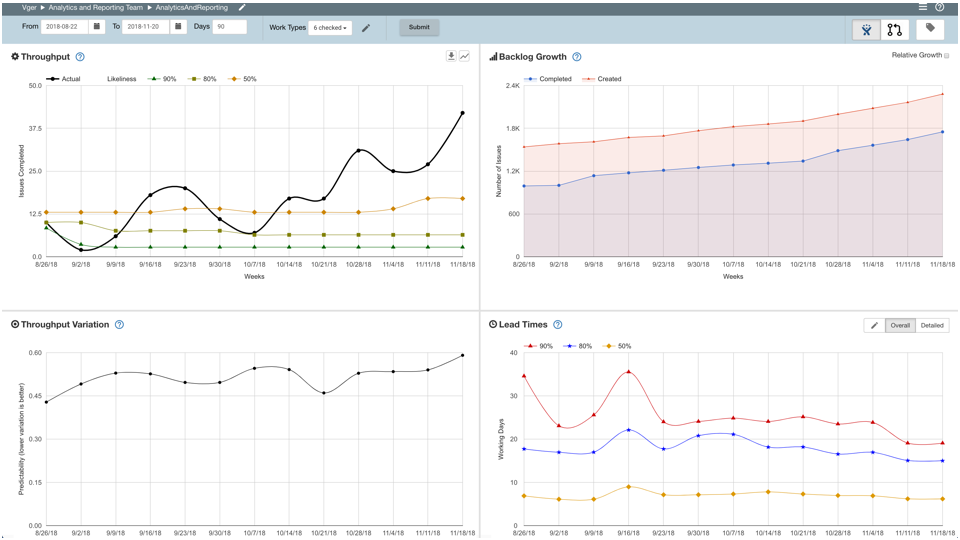
We once conducted a retrospective where a topic of discussion was brought up among a couple of engineers where some voiced their opinion that our work and momentum had slowed over the past month (basically, some felt we were getting less and less done, while engineering resources and work remained rather constant).
This could have been a controversial topic to breech. However, within the discussion, we had metrics handy to answer whether this was the case or not.
By having metrics readily available that measured both work in progress versus work items completed and comparing that to commit history for our project and then being able to compare these metrics against those from the previous month, we found that:
- Our commit history had in fact increased
- Our average stories completed had remains relatively constant across both periods.
We tabled this discussion at this point (importance of a moderator at work!) but further investigation led to the fact that basically while we were working our butts off, our stories were becoming larger and more complex – which led to us targeting in a future retrospective, that we needed to reconsider how we conducted our planning meetings
TL:DR stories weren’t being broken down into sub tasks as much as they should have been. Work items ballooned in scope and reflectively were bogged down on our Kanban board.
Now… figuring out what metrics you may need is probably going to be a challenge. This is something that can be very different from team to team. However, there are two rules you may want to keep in mind when sourcing metrics for your retrospectives:
- Agree as a team what metrics are important
- Imperfect visibility is better than zero visibility
Basically, whatever heuristic you decide on using – it needs to be something that makes sense to the whole team. This in itself could be a great topic for its own retrospective.
By imperfect visibility versus zero visibility, even if your chosen metrics aren’t exhaustive (better for your retro that they’re quick and easy to digest), having some level of metrics is better than having none. It’s hard to argue with math – even if that math is the equivalent of 1 + 1 = 2.
Some metrics we’ve used – just to give you some ideas:
- Total number of stories committed to per period
- Number of stories completed (cross-referenced with commits)
- Average number of stories in progress during period
- Number of stories completed based on service level (P1s vs P3s vs “DO IT NAO!”)
- Lead time of stories from their committed state to their finished state (however your team defines that)
Again, whatever you chose to use – be careful of diving too deep for your retrospective and be sure to make that choice as a team.
Combo Breaker:
In our last retrospective, we did something different. Rather than follow the format provided in the previous we performed a recursive retrospective by looking back at the results of our retrospectives from the beginning of the year. Time for a Scala joke!
 We've already blown our quota for this joke
We've already blown our quota for this joke
As indicated above, we came up with some deep, recursive improvements. Here’s some steps you can follow to do the same:
- Prior to the upcoming retrospective, we review notes taken from the prior retrospective sessions
- Try to target a time-frame that makes sense for your team (e.g. last quarter, last calendar year, previous geological epoch, etc.)
- Note the well-done items and the need-to-improve ones
- Look for repeating patterns as this is key (no, StackOverflow doesn’t have a regex for this – trust me, I looked).
- Compile these repeating patterns from previous retrospectives into a small list and bring that to the retrospective.
In the retrospective, instead of following the same procedure your team is no doubt already movin’ and groovin’ to, you can present to this this list (bonus points if you preface this by abruptly jumping atop the nearest available piece of Herman Miller furniture in your office and shouting, “Co-co-co-co-co-co Combo breaker!!!!“).
 Shameless pandering to 90s gaming nostalgia
Shameless pandering to 90s gaming nostalgia
Actually, no bonus points will be awarded. However, depending on the demeanor of your co-workers, you may be cheered, you may get a laugh, or may be straight up escorted from the building. Either way, it’s going to be a fun rest of the day for you.
Instead of sourcing consent from the team (you’ve effectively already done this with your previous retrospectives) go over the take-aways from each previous retro session. Briefly discuss the following:
- Of the Things we did well, are we still doing them well?
- Of the things we needed to improve on – did we improve (DWYSYWD **)?
- For any item the team answered, “no” for – as a team, pick one of these items for discussion.
From here, continue the retrospective as you would normally run it – discuss what steps need to be taken to improve on your topic of focus, create and assign action items, etc. (don’t forget to take notes).
This technique I’ve found helps accomplish three things:
- Its handy when pressed for time – as you’re effectively dog-fooding your own previous retrospectives, a lot of the consensus building for the sessions is taken care of.
- It’s a change of pace – Hey, people get bored with routine. Breaking routine also often lends to new avenues of thinking.
- Shores up gaps – Let’s be honest, at some point, your team will commit to an item of improvement that is going to take several passes at solving. Here’s how you can make sure you’re not leaving something on the table. ***

** (Do What You Said You Would Do – Don’t you dig complex acronyms?)
*** If you seriously accomplish every single item of improvement your team targets every time, all the time, congratulations, you’re some kind of unicorn collective. Give yourselves a high five or whatever it is unicorns do.
 High five!
High five!
For those who read and enjoyed the previous dive into conducting retrospectives, hopefully this post has given you some insight on how to further fine-tune the process and improve how you and your team improve.
 You weren’t getting away without a parting shot from this guy
You weren’t getting away without a parting shot from this guy

































{kind=link}