Discover how Bazaarvoice migrated millions of UGC records from RDS MySQL to AWS Aurora – at scale and with minimal user impact. Learn about the technical challenges, strategies, and outcomes that enabled this ambitious transformation in reliability, performance, and cost efficiency
Bazaarvoice ingests and serves millions of user-generated content (UGC) items—reviews, ratings, questions, answers, and feedback—alongside rich product catalog data for thousands of enterprise customers. This data powers purchasing decisions for consumers and delivers actionable insights to clients. As e‑commerce volume and catalog breadth grew, our core transactional datastore on Amazon RDS for MySQL approached operational limits. Performance bottlenecks and scale risks were not acceptable for downstream systems or client-facing SLAs.
This post describes why we moved, what we ran before, the constraints we hit, and how a two‑phase modernization—first standardizing on MySQL 8.0, then migrating to Amazon Aurora MySQL—unlocked scale, resiliency, and operational efficiency.
Technical drivers for migration
Our decision was driven by clear, repeatable pain points across regions and clusters:
- Elasticity and cost efficiency: RDS tightly couples compute and storage; scaling IOPS forced larger instances even when CPU/RAM headroom was unnecessary, leading to overprovisioning and costly peak-capacity sizing.
- Read scalability and freshness: Minutes of replica lag during heavy write bursts degraded downstream experiences and analytics.
- Operational agility: Routine maintenance (major/minor upgrades, index/build operations) required long windows and coordination, increasing risk and toil.
- Availability and recovery: We needed stronger RTO (Recovery Time Objective)/RPO (Recovery Point Objective) posture across AZs (Availability Zones)/regions with simpler failover.
- Currency and security: MySQL 5.7 end of life increased support cost and security exposure.
Current architecture (before)
This design served us well, but growth revealed fundamental constraints.
Our PRR (Product Reviews & Ratings) platform ran a large fleet of Amazon RDS for MySQL clusters deployed in the US and EU for latency and data residency. Each cluster had a single primary (writes) and multiple read replicas (reads), with application tiers pinned to predefined replicas to avoid read contention.
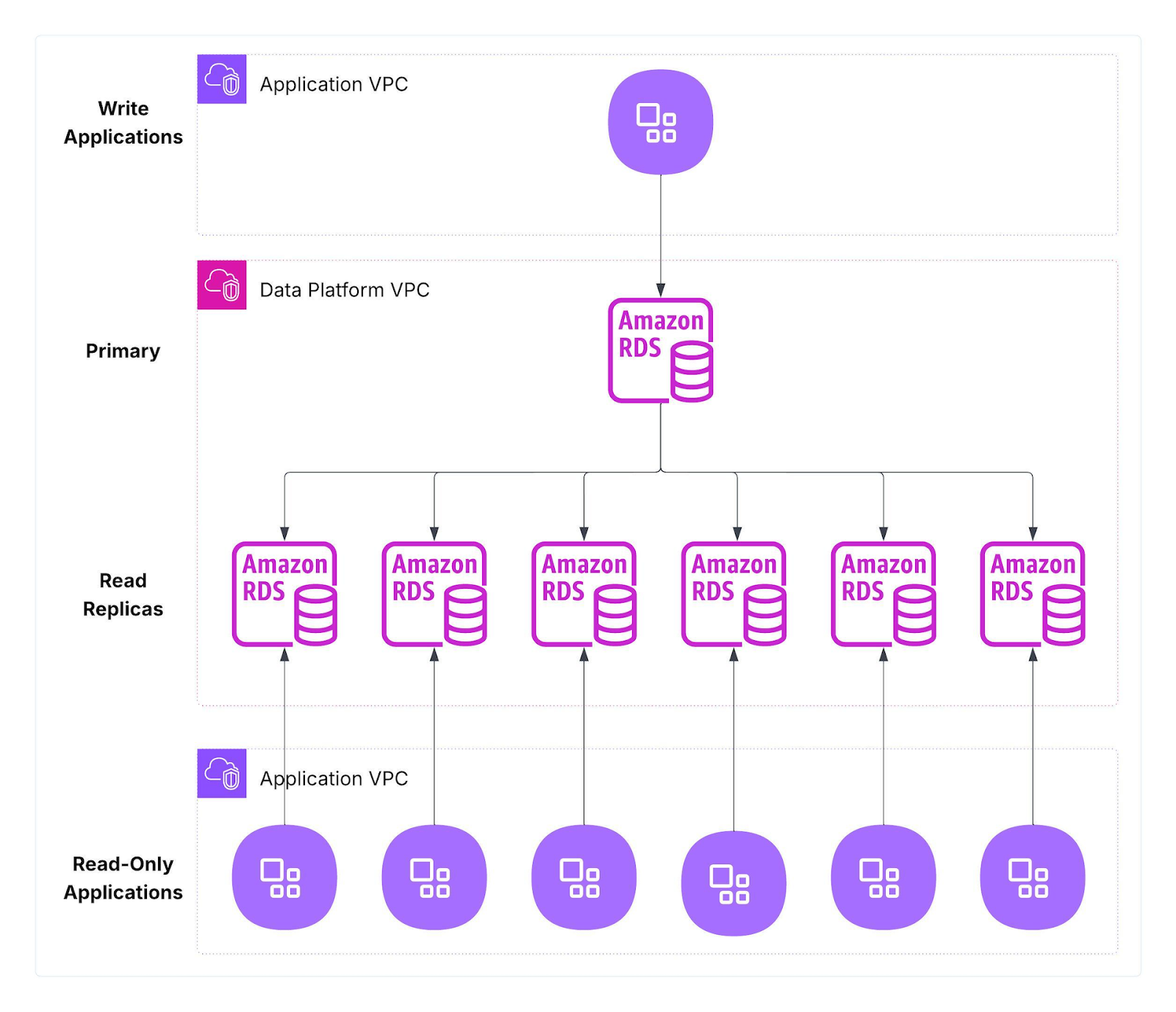
Figure 1: Previous RDS-based architecture
Observed Constraints and impact
- Elasticity and cost: To gain IOPS we upsized instances despite CPU/RAM headroom, leading to 30–50% idle capacity off‑peak; resizing required restarts (10–30 min impact).
- Read scalability and freshness: Under write bursts, replica lag p95 reached 5–20 minutes; read‑after‑write success fell below 99.5% at peak; downstream analytics SLAs missed.
- Operational agility: Multi‑TB index/DDL work consumed 2–6 hours/change; quarterly maintenance totaled 8–12 hours/cluster; change failure rate elevated during long windows.
- Availability and recovery: Manual failovers ran 3–10 minutes (RTO); potential data loss up to ~60s (RPO) during incidents; cross‑AZ runbooks were complex.
- Large‑table contention: Long scans increased lock waits and p95 query latency by 20–40% during peaks.
- Platform currency: MySQL 5.7 EOL increased support, security exposure and extended support costs.
Our modernization plan
We executed a two‑phase approach to de‑risk change and accelerate value:
- Upgrade all clusters to MySQL 8.0 to eliminate EOL risk, unlock optimizer and engine improvements, and standardize client compatibility.
- Migrate to Amazon Aurora MySQL to decouple compute from storage, minimize replica lag, simplify failover, and reduce operational overhead.
The below diagram illustrates our target Aurora Architecture.
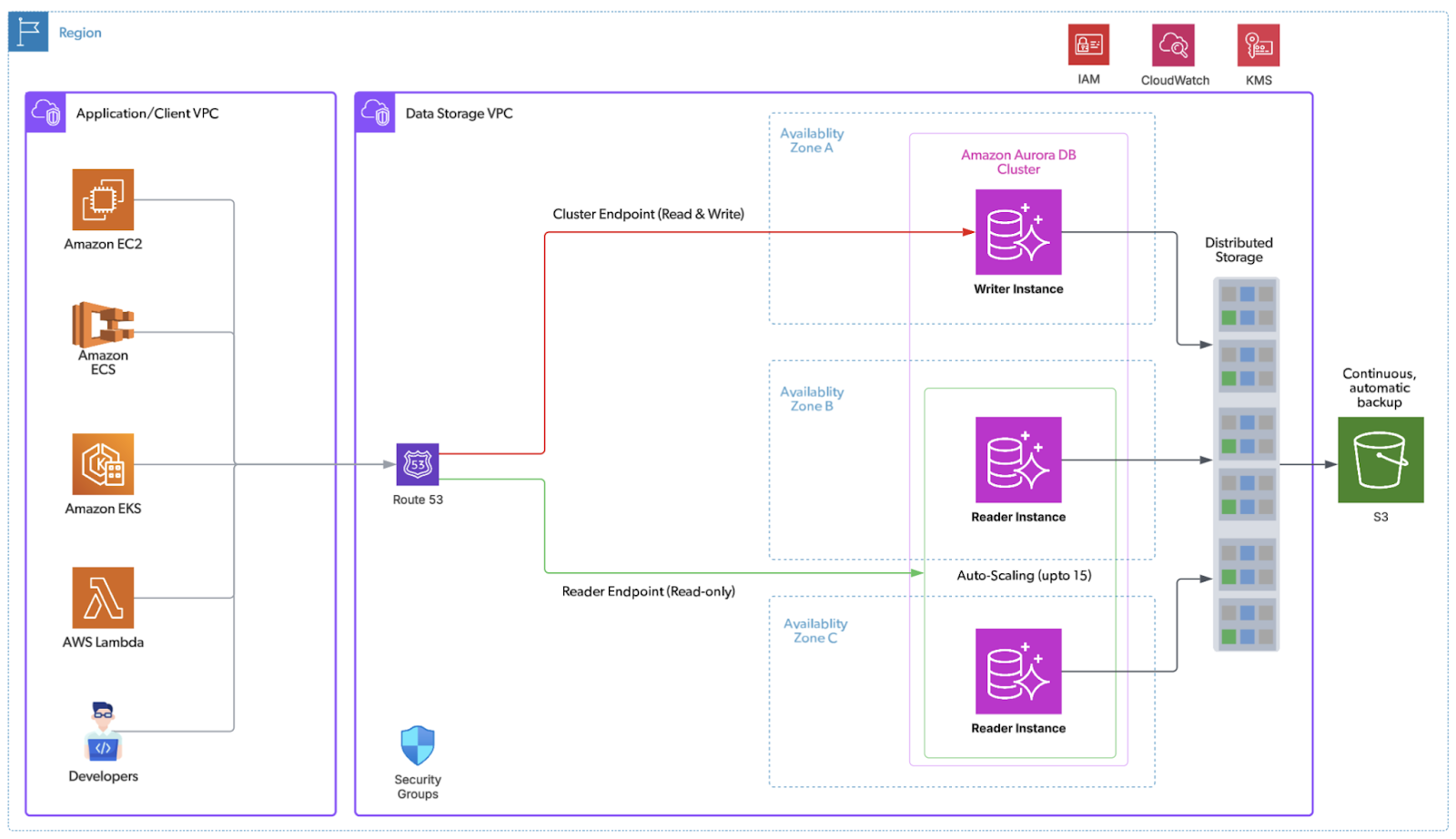
Figure 2: Target Aurora-based architecture
Phase 1: Upgrading From MySQL 5.7 to MySQL 8.0 (blue‑green)
Objective: Achieve currency and immediate performance/operability wins with minimal downtime.
Approach
- Stood up a parallel “green” MySQL 8.0 environment alongside the existing 5.7 “blue”.
- Ran compatibility, integration, and performance tests against green; validated drivers and connection pools.
- Orchestrated cutover: freeze writes on blue, switch application endpoints to green, closely monitor, then decommission.
- Rollback strategy: No supported downgrade from 8.0 to 5.7; keep blue (5.7) intact and time‑box a 4‑hour rollback window during low traffic; on SLO regression set green read‑only, switch endpoints back to blue, re‑enable writes, and reconcile by replaying delta transactions from the upstream cache.
Key considerations and fixes
- SQL and deprecated features: Refactored incompatible queries and stored routines; reviewed optimizer hints.
- Character set: Validated/standardized on utf8mb4; audited column/ index lengths accordingly.
- Authentication: Planned client updates for 8.0’s default caching_sha2_password vs mysql_native_password.
- Auto‑increment lock mode: Verified innodb_autoinc_lock_mode defaults and replication mode to avoid duplicate key hazards.
- Regular expression guards: Tuned regexp_time_limit / regexp_stack_limit where long‑running regex filters were valid.
- Buffer pool warm state: Tuned innodb_buffer_pool_load_at_startup to preload hot pages on startup for faster warmup; paired with innodb_buffer_pool_dump_at_shutdown to persist cache at shutdown.
Outcome
- Downtime kept to minutes via blue‑green cutover.
- Immediate benefits from 8.0: improved optimizer, JSON functions, CTEs/window functions, better instrumentation.
- Reduced future migration risk by standardizing engines and drivers ahead of Aurora Migration.
The below diagram illustrates the above RDS MySQL upgradation path.
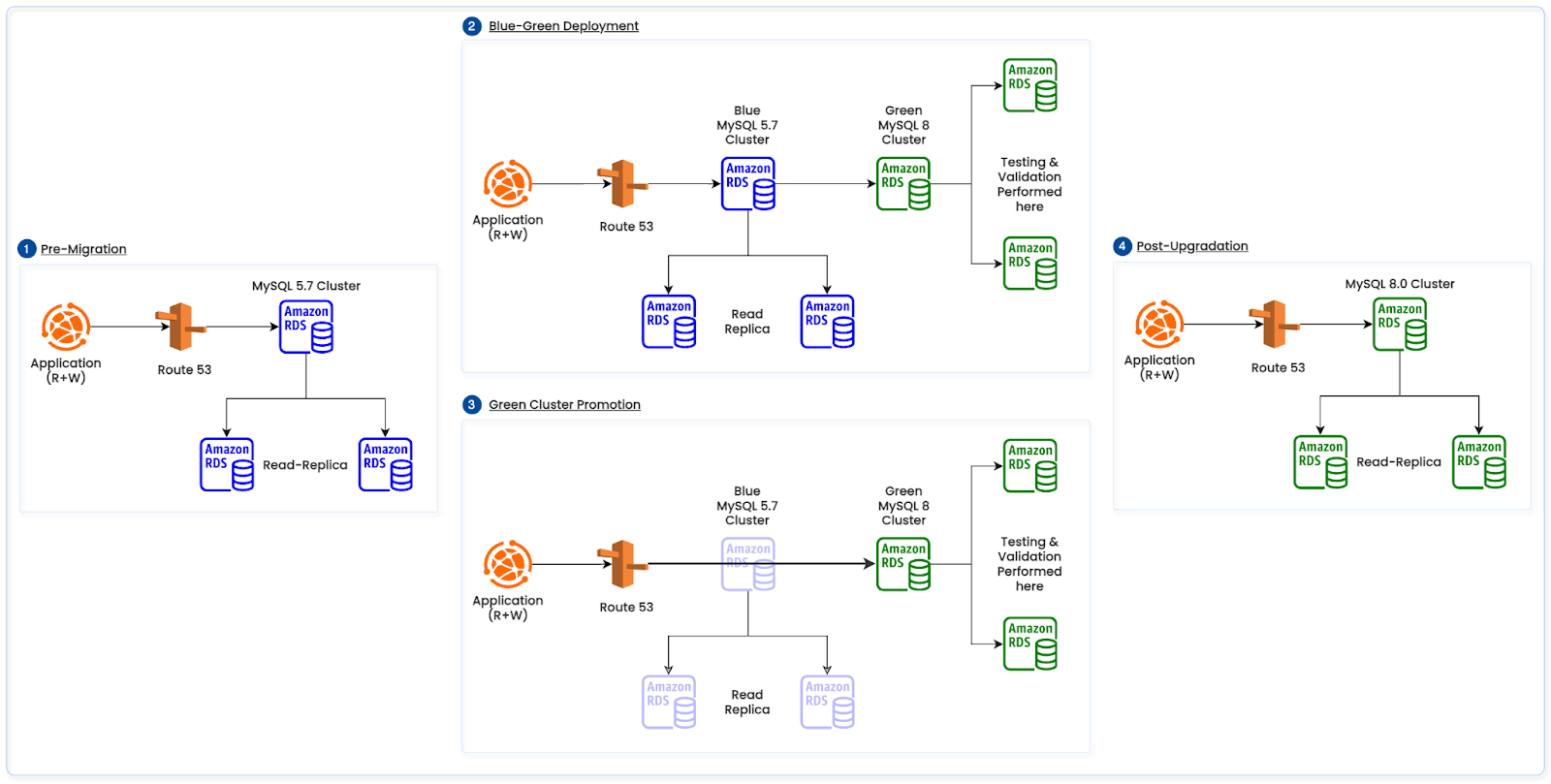
Figure 3: MySQL 5.7 to MySQL 8.0 Upgradation Path
Phase 2: Migrating to Aurora MySQL (minimal downtime)
Why Amazon Aurora MySQL
Aurora’s cloud-native architecture directly addresses the core constraints—scalability, cost and operational inefficiencies, and replication/high availability—outlined in the Technical Drivers for Migration section.
- Decoupled compute and storage: Writer and readers share a distributed, log‑structured storage layer that auto‑scales in 10‑GB segments, with six copies across three AZs.
- Near‑zero replica lag: Readers consume the same storage stream; typical lag is single‑digit milliseconds.
- Fast, predictable failover: Reader promotion is automated; failovers complete in seconds with near‑zero data loss (strong RPO/RTO posture). For further reading Aurora DB Cluster – High Availability
- Right‑sized elasticity: Independently scale read capacity; add/remove readers in minutes without storage moves.
- Operational simplicity: Continuous backups to S3, point‑in‑time restore, fast database cloning (copy‑on‑write) for testing/ops.
- Advanced capabilities: Parallel Query for large scans, Global Database for cross‑region DR, and optional Serverless v2 for spiky workloads.
Migration Strategy
Our goal is a low-downtime move from RDS MySQL to Aurora MySQL and keeping a fast rollback path.
- Minimize write downtime and application risk.
- Maintain an immediate rollback option.
Migration Path
- Source RDS (STATEMENT): Maintain the primary on STATEMENT binlog_format to satisfy existing downstream ETL requirements.
- ROW bridge replica (RDS): Create a dedicated RDS read replica configured with:
- binlog_format=ROW
- log_slave_updates=1
- binlog_row_image=FULL
This emits row-based events required for Aurora Replica Cluster replication changing the primary.
Validation and query replay (pre-cutover)
- Parity checks: Continuous row counts/checksums on critical tables; spot data sampling.
- Shadow reads: Route a portion of read traffic to the Aurora reader endpoint; compare results/latency.
- Query replay: Capture representative workload (from binlogs/proxy mirror) and replay against Aurora to validate execution plans, lock behavior, and performance.
- Real-time replication monitoring: Continuously track replication lag, error rates, and binlog position between RDS and Aurora to ensure data consistency and timely sync before cutover.
Traffic shift and promotion
- Phase 1 — Shift reads: Gradually route read traffic to the Aurora reader endpoint; monitor replica lag, p95/p99 latency, lock waits, and error rates.
- Phase 2 — Promote: Promote the Aurora replica cluster to a standalone Aurora DB cluster (stop external replication).
- Phase 3 — Shift writes: Redirect application writes to the Aurora writer endpoint; keep reads on Aurora readers.
Operational safeguards
- Coordination: Quiesce non‑critical writers and drain long transactions before promotion.
- DNS endpoint management: Before migration, set the DNS TTL to 5 seconds to enable rapid propagation. Update the existing DNS CNAME to point to Aurora cluster endpoints during cutover, then revert as needed for rollback.
- Config hygiene: Update connection strings/secrets atomically; ensure pools recycle to pick up new endpoints.
- Monitoring: Watch replica lag, query latency, deadlocks, and parity checks throughout and immediately after cutover.
- Rollback: If SLOs degrade or parity fails, redirect writes back to RDS; the standby rollback replica can be promoted quickly for clean fallback.
- Runbooks: Every migration step was governed by clear-cut runbooks, practiced and tested in advance using a parallel setup to ensure reliability and repeatability.
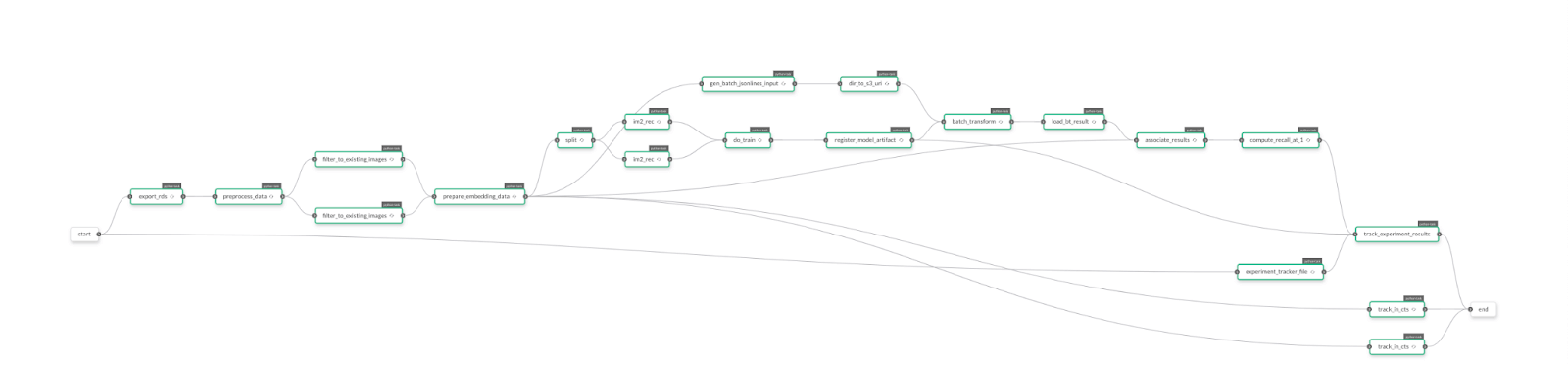
The below diagram illustrates the above RDS MySQL to Aurora MySQL migration path.
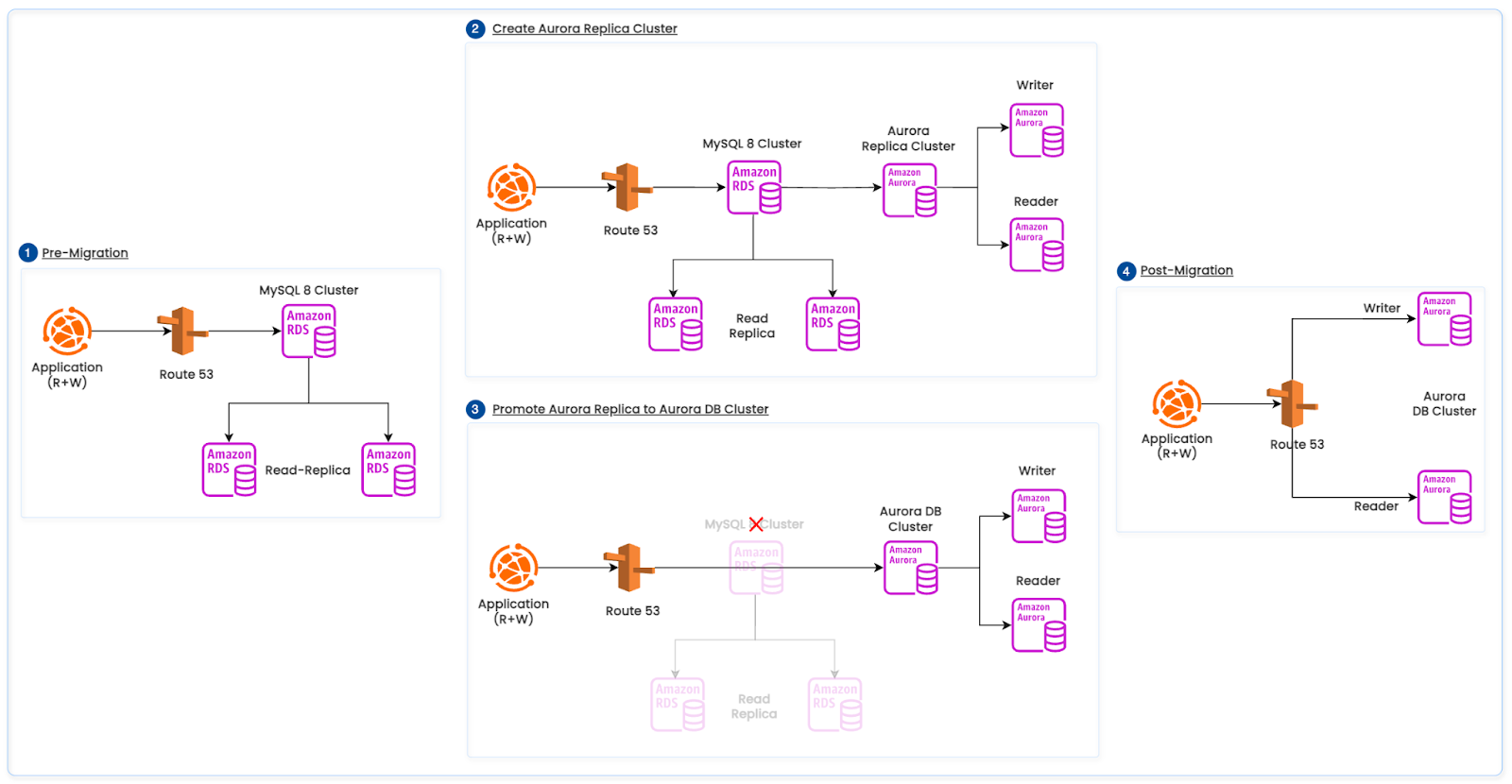
Figure 4: RDS MySQL to Aurora MySQL Migration Path
Results and what improved
- Data freshness: Replica lag = 0s; read-after-write ≥ 99.9%; analytics staleness p95 ≤ 5 min.
- Scalability: Read scaling efficiency ≥ 0.8; writer CPU ≤ 70%.
- Availability: RTO p95 ≤ 30s; RPO ≤ 1s; observed availability ≥ 99.95%.
- Operability: PITR restore ≤ 15 min; fast clone ≤ 60s; maintenance time −50% vs. baseline.
- Cost alignment: No storage over provisioning – Replicas reduced from 7 to 1, yielding ~40% total cost reduction.
What Made Our Aurora Migration Unique to Bazaarvoice
While Aurora’s scalability and reliability are well known, our implementation required engineering solutions tailored to Bazaarvoice’s scale, dependencies, and workloads:
- Foundational discovery: Three months of in-depth system analysis to map every dependency — the first such effort for this platform — ensuring a migration with zero blind spots.
- Large-scale dataset migration: Handled individual tables measured in terabytes, requiring specialized sequencing, performance tuning, and failover planning to maintain SLAs.
- Replica optimization: Reduced the read replica footprint through query pattern analysis and caching strategy changes, delivering over 50% cost savings without performance loss.
- Beyond defaults: Tuned Aurora parameters such as auto_increment_lock_mode and InnoDB settings to better match our workload rather than relying on out-of-the-box configurations.
- Replication format constraint: Our source ran statement-based replication with ETL triggers on read replicas, which meant we couldn’t create an Aurora reader cluster directly. We engineered a migration path that preserved ETL continuity while moving to Aurora.
- Custom workload replay tooling: Developed scripts to filter RDS-specific SQL from production query logs before replaying in Aurora, enabling accurate compatibility and performance testing ahead of staging.
- Environment-specific tuning: Applied different parameter groups and optimization strategies for QA, staging, and production to align with their distinct workloads.
These deliberate engineering decisions transformed a standard Aurora migration into a BV-optimized, cost-efficient, and risk-mitigated modernization effort.
Learnings and takeaways
- Standardize early to remove surprises: Commit to utf8mb4 (with index length audits), modern auth (caching_sha2_password), and consistent client libraries/connection settings across services. This eliminated late rework and made test results portable across teams.
- Build safety into rollout, not after: Shadow reads and row‑level checksums caught drift before cutover; plan diffs and feature flags kept risk bounded. Go/no‑go gates were tied to SLOs (p95 latency, error rate), not gut feel, and a rehearsed rollback made the decision reversible.
- Rollback is a design requirement: With no supported 8.0→5.7 downgrade, we ran blue‑green, time‑boxed a 4‑hour rollback window during low traffic, kept low DNS/ALB TTLs, and pre‑captured binlog coordinates. On regression: set green read‑only, flip endpoints to blue, re‑enable writes, then reconcile by replaying delta transactions from the upstream cache.
- Backward replication helps but is brittle: Short‑lived 8.0‑primary→5.7‑replica mirroring de‑risked bake windows, yet required strict session variable alignment and deferring 8.0‑only features until validation completed.
- Partition first, automate always: Domain partitioning lets us upgrade independently and reduce blast radius. Automation handled drift detection, endpoint flips, buffer pool warm/cold checks, and post‑cutover validation so humans focused on anomalies, not checklists.
- Operability hygiene pays compounding dividends: Keep transactions short and idempotent; enforce parameter discipline; cap runaway regex (regexp_time_limit/regexp_stack_limit); validate autoinc lock mode for your replication pattern; and keep instances warm by pairing innodb_buffer_pool_dump_at_shutdown with innodb_buffer_pool_load_at_startup. Snapshots + PITR isolated heavy work, and regular failover drills made maintenance predictable.
- Measurable outcome: Replica lag dropped to milliseconds; cutovers held downtime to minutes; read scale‑out maintained p95 latency within +10% at target QPS with writer CPU ≤ 70% and read scaling efficiency ≥ 0.8; replicas reduced from 7 to 1, driving ~40% cost savings.
Conclusion
The strategic migration from Amazon RDS to Amazon Aurora MySQL was a significant milestone. By upgrading to MySQL 8.0 and then migrating to Aurora, we successfully eliminated replication bottlenecks and moved the responsibility for durability to Aurora’s distributed storage. This resulted in tangible benefits for our platform and our customers, including:
- Improved Data Freshness: Replica lag was reduced to milliseconds, significantly improving downstream analytics and client experiences.
- Enhanced Scalability and Cost Efficiency: We can now right-size compute resources independently of storage, avoiding over-provisioning for storage and IOPS. Read capacity can also be scaled independently.
- Higher Availability: The architecture provides faster failovers and stronger multi-AZ durability with six-way storage replication.
- Simplified Operations: Maintenance windows are shorter, upgrades are easier, and features like fast clones allow for safer experimentation.
This new, resilient, and scalable platform gives us the freedom to move faster with confidence as we continue to serve billions of consumers and our customers worldwide.
Acknowledgements
This milestone was possible thanks to many people across Bazaarvoice — our Database engineers, DevOps/SRE, application teams, security and compliance partners, product, principal engineering community and leadership stakeholders. Thank you for the rigor, patience, and craftsmanship that made this transition safe and successful.