
At Bazaarvoice, we’ve pulled off an incredible feat, one that is such an enormous task that I’ve seen other companies hesitate to take on. We’ve learned a lot along the way and I wanted to share some of these experiences and lessons in hopes they may benefit others facing similar decisions.
The Beginning
Our original Product Ratings and Review service served us well for many years, though eventually encountered severe scalability challenges. Several aspects we wanted to change: a monolithic Java code base, fragile custom deployment, and server-side rendering. Creative use of tenant partitioning, data sharding and horizontal read scaling of our MySQL/Solr based architecture allowed us to scale well beyond our initial expectations. We’ve documented how we have accomplished this scaling on our developer blog in several past posts if you’d like to understand more. Still, time marches on and our clients have grown significantly in number and content over the years. New use cases have come along since the original design: emphasis on the mobile user and responsive design, accessibility, the emphasis on a growing network of consumer generated content flowing between brands and retailers, and the taking on of new social content that can come in floods from Twitter, Instagram, Facebook, etc.
As you can imagine, since the product ratings and reviews in our system are displayed on thousands of retailer and brand websites around the world, the read traffic from review display far outweighs the write traffic from new reviews being created. So, the addition of clusters of Solr servers that are highly optimized for fast queries was a great scalability addition to our solution.
A highly simplified diagram of our classic architecture:
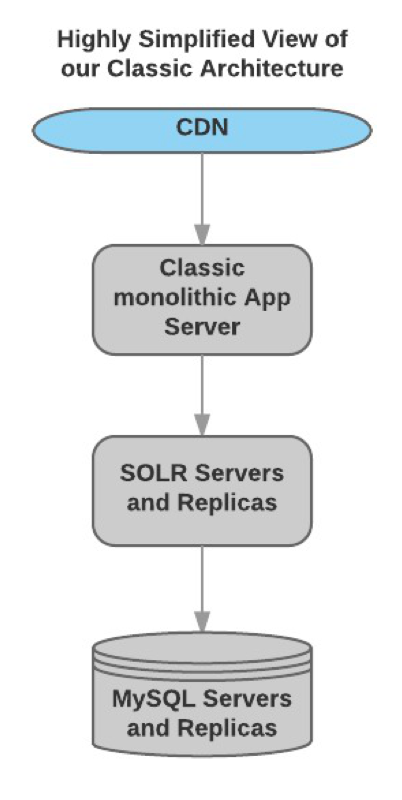
However, in addition to fast review display when a consumer visited a product page, another challenge started emerging out of our growing network of clients. This network is comprised of Brands like Adidas and Samsung who collect reviews on their websites from consumers who purchased the product and then want to “syndicate” those reviews to a set of retailer ecommerce sites where shoppers can benefit from them. Aside from the challenges of product matching which are very interesting, under the MySQL architecture this could mean the reviews could be copied over and over throughout this network. This approach worked for several years, but it was clear we needed a plan for the future.
As we grew, so did the challenge of an expanding volume of data in the master databases to serve across an expanding network of clients. This, together with the need to deliver more front-end web capability to our customers, drove us to what I hope you will find is a fascinating story of rearchitecture.
The Journey Begins
One of the first things we decided to tackle was to start moving analytics and reporting off the existing platform so that we could deliver new insights to our clients showing how reviews are used by shoppers in their purchase decisions. This choice also enabled us to decouple the architecture and spin up parallel teams to speed delivery. To deliver these capabilities, we adopted big data architectures based on Hadoop and HBase to be able to assimilate hundreds of millions of web visits into analytics that would paint the full shopper journey picture for our clients. By running map reduce over the large set of review traffic and purchase data, we are able to give our clients insight into these shopper behaviors and help our clients better understand the return on investment they receive from consumer generated content. As we built out this big data architecture, we also saw the opportunity to offload reporting from the review display engine. Now, all our new reporting and insight efforts are built off this data and we are actively working to move existing reporting functionality to this big data architecture.
On the front end, flexibility and mobile was a huge driver in our rearchitecture. Our original template-driven, server-side rendering can provide flexibility, but that ultimate flexibility is only required in a small number of use cases. For the vast majority, a client-side rendering via javascript with behavior that can be configured through a simple UI would yield a better mobile-enabled shopping experience that’s easier for clients to control. We made the call early on not to try to force migration of clients from one front end technology to another. For one thing, it’s not practical for a first version of a product to be 100% feature function capable to the predecessor. For another, there was just simply no reason to make clients choose. Instead, as clients redesigned their sites and as new clients were onboard, they opt’ed in to the new front end technology.
We attracted some of the top javascript talent in the country to this ambitious undertaking. There are some very interesting details of the architecture we built that have been described on our developer blog and that are available as open source projects on in our bazaarvoice github organization. Look for the post describing our Scoutfile architecture in March of 2015. The BV team is committed to giving back to the Open Source community and we hope this innovation helps you in your rearchitecure journey.
On the backend, we took inspiration from both Google and Netflix. It was clear that we needed to build an elastic, scalable, reliable, cloud-based data store and query layer. We needed to reorganize our engineering team into autonomous service oriented teams that could move faster. We needed to hire and build new skills in new technologies. We needed to be able to roll this out as transparently as possible to our clients while serving live shopping traffic so no one knows its happening at all. Needless to say, we had our work cut out for us.
For the foundation of our new architecture, we chose Cassandra, an Open Source NoSQL data solution based on influence of ideas from Google and their BigTable architecture. Cassandra had been battle hardened at Netflix and was a great solution for a cloud resilient, reliable storage engine. On this foundation we built a service we call Emo, originally intended for sentiment analysis. As we made progress towards delivery, we began to understand the full potential of Cassandra and its NoSQL based architecture as our primary display storage.
With Emo, we have solved the potential data consistency issues of Cassandra and guarantee ACID database operations. We can also seamlessly replicate and coordinate a consistent view of all the rating and review data across AWS availability zones worldwide, providing a scalable and resilient way to serve billions of shoppers. We can also be selective in the data that replicates for example from the European Union (EU) so that we can provide assurances of privacy for EU based clients. In addition to this consistency capability, Emo provides a databus that allows any Bazaarvoice service to listen for the kinds of changes the service particularly needs, perfect for a new service oriented architecture. For example, a service can listen for the event of a review passing moderation which would mean that it should now be visible to shoppers.
While Emo/Cassandra gave us many advantages, its NoSQL query capability is limited to what Cassandra’s key-value paradigm. We learned from our experience with Solr that having a flexible, scalable query layer on top of the master datastore resulted in significant performance advantages for calculating on-demand results of what to display during a shopper visit. This query layer naturally had to provide the distributed advantages to match Emo/Cassandra. We chose ElasticSearch for our architecture and implemented a flexible rules engine we call Polloi to abstract the indexing and aggregation complexities away from engineers on teams that would use this service. Polloi hooks up to the Emo databus and provides near real time visibility to changes flowing into Cassandra.
The rest of the monolithic code base was reimplemented into services as part of our service oriented architecture. Since your code is a direct reflection of the team, as we took on this challenge we formed autonomous teams that owned everything full cycle from initial conception to operation in production. We built the teams with all the skills needed for success: product owners, developers, QA engineers, UX designers (for front end), DevOps engineers, and tech writers. We built services that managed the product catalog, UI Configuration, syndication edges, content moderation, review feeds, and many more. We have many of these rearchitected services now in production and serving live traffic. Some examples include services that perform the real time calculation of what Brands are syndicating consumer generated content to which Retailers, services that process client product catalog feeds for 100s of millions of products, new API services, and much more.
To make all of the above more interesting, we also created this service-oriented architecture to leverage the full power of Amazon’s AWS cloud. It was clear we had the uncommon opportunity to build the platform from the ground up to run in the cloud with monitoring, elastic resiliency, and security capabilities that were unavailable in previous data center environments. With AWS, we can take advantage of new hardware platforms with a push of a button, create multi datacenter failover capabilities, and use new capabilities like elastic MapReduce to deliver big data analytics to our clients. We build auto-scaling groups that allow our services to automatically add compute capacity as client traffic demands grow. We can do all of this with a highly skilled team that focuses on delivering customer value instead of hardware procurement, configuration, deployment, and maintenance.
So now after two plus years of hard work, we have a modern, scalable service-oriented solution that can mirror exactly the original monolithic service. But more importantly, we have a production hardened new platform that we will scale horizontally for the next 10 years of growth. We can now deliver new services much more quickly leveraging the platform investment that we have made and deliver customer value at scale faster than ever before.
So how did we actually move 300 million shoppers without them even knowing? We’ll take a look at this in an upcoming post!
authored by Gary Allison