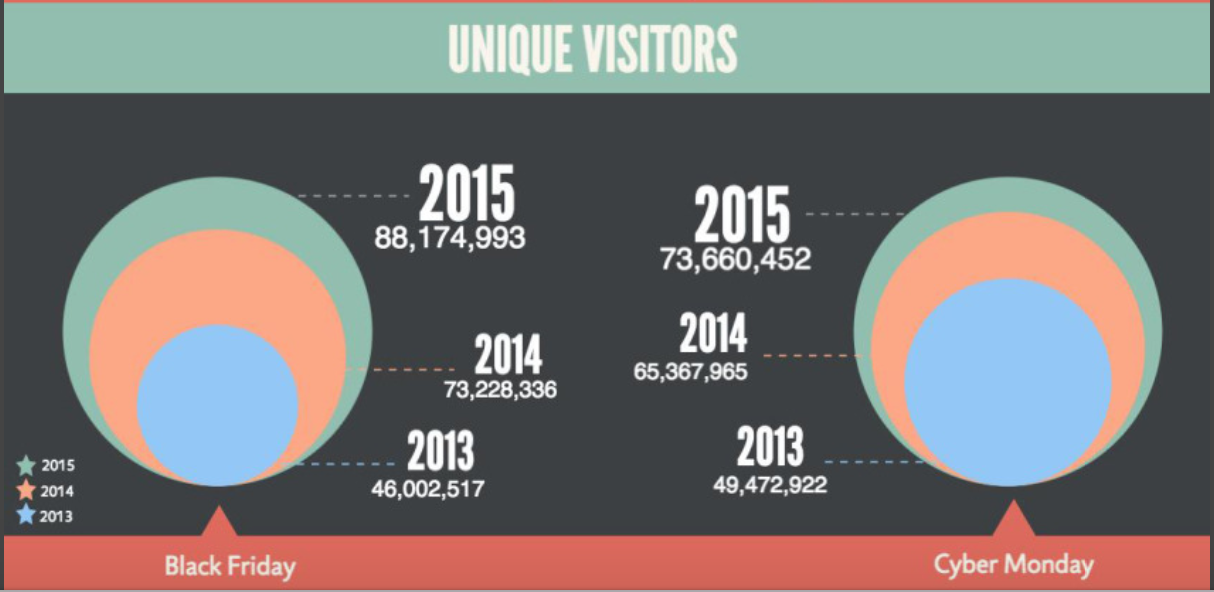
As the summer comes to an end, so do the internships for numerous university students here at Bazaarvoice. This past week, the interns were given an opportunity to present a summary of their accomplishments. This afternoon of presentations, known as the Bazaarvoice “Intern Demo Day”, highlighted the various achievements throughout the company, not just in the R&D department.
The following is a short summary of the great work our interns complete this summer as well as some images from the “Intern Demo Day”.
CHASE PORTER: My project, which I have named “The Great (red)Shift”, is intended to improve data accessibility for computed aggregated counts of various canonical events written to HBase. To do this I designed a data warehouse in Amazon Redshift that I loaded with transformed aggregated counts extracted from the tables in HBase. This makes the counts readily SQL query-able in an incredibly fast system whereas before they had to be computed with performance heavy queries from Raw Logs generated by Cookie Monster. The biggest block for this project was in processing the data from HBase which was stored as serialized bytes and needed to be handled uniquely for different types of canonical events (i.e. pageviews, impressions, features) to translate into a readable form for Redshift.
BEN DEVORE: My product is web crawler written in node.js that scrapes clients’ webpages for product data in order to build their product feeds for them. For many of Bazaarvoice’s smaller clients, building and maintaining their product feed is a significant obstacle in the onboarding process. This tool aims to clear that obstacle by taking this task out of there hands.
STONEY MCCRARY: So I have been fortunate enough to get to work on several different pieces in curations but I am going to talk on what I have been hammering on for the last couple of weeks. More and more of our high volume clients are receiving millions of hits a day and this has caused performance to become a higher priority problem for them. In response to this, we are focusing our efforts on building a new display with performance in mind. Performance for the display centers around only providing the minimal amount of data needed and supply the rest as necessary. The piece I will be showing is the display carousel and how it dynamically loads and dumps the data to allow for faster loading and to keep browser memory low.
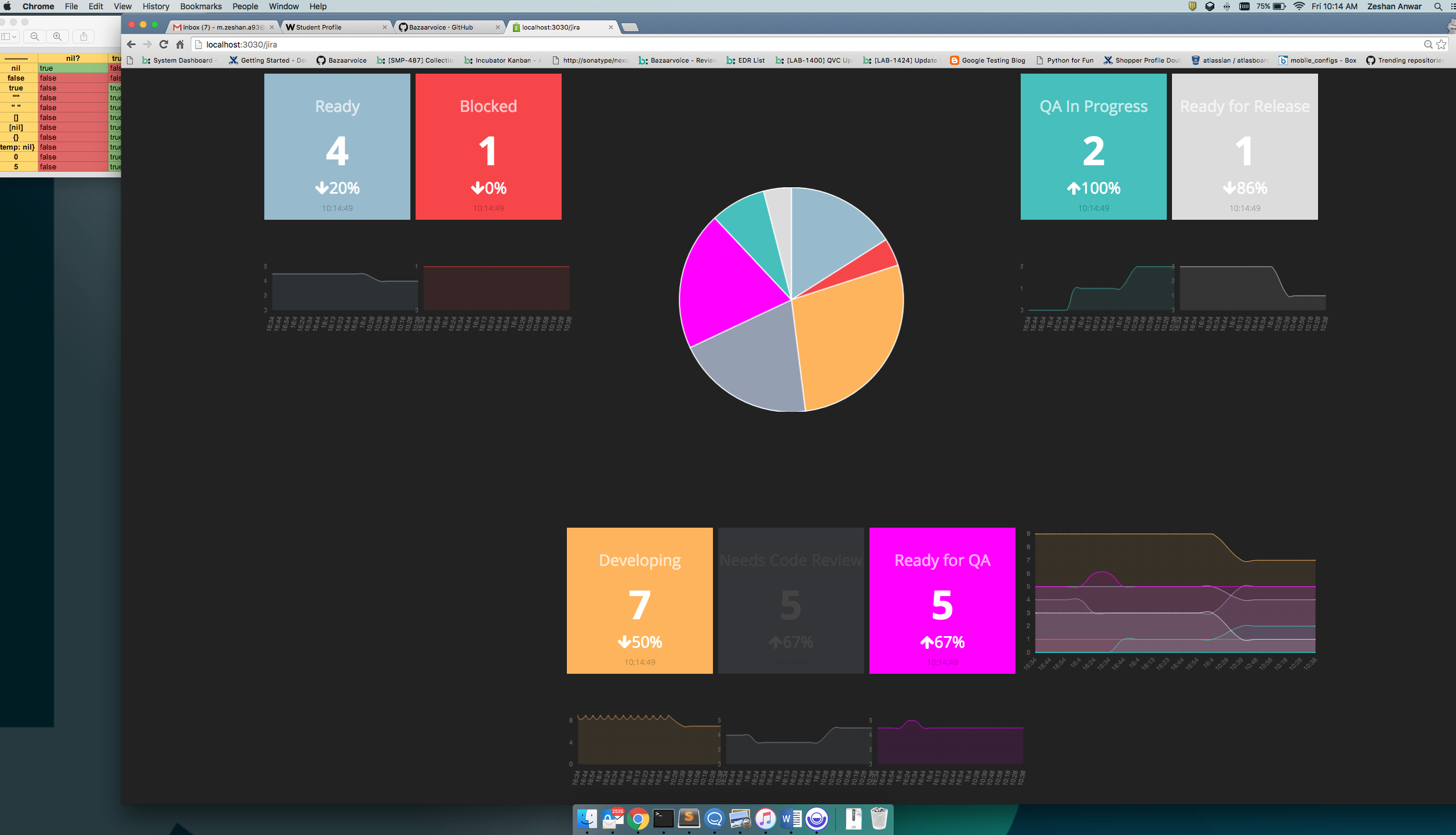
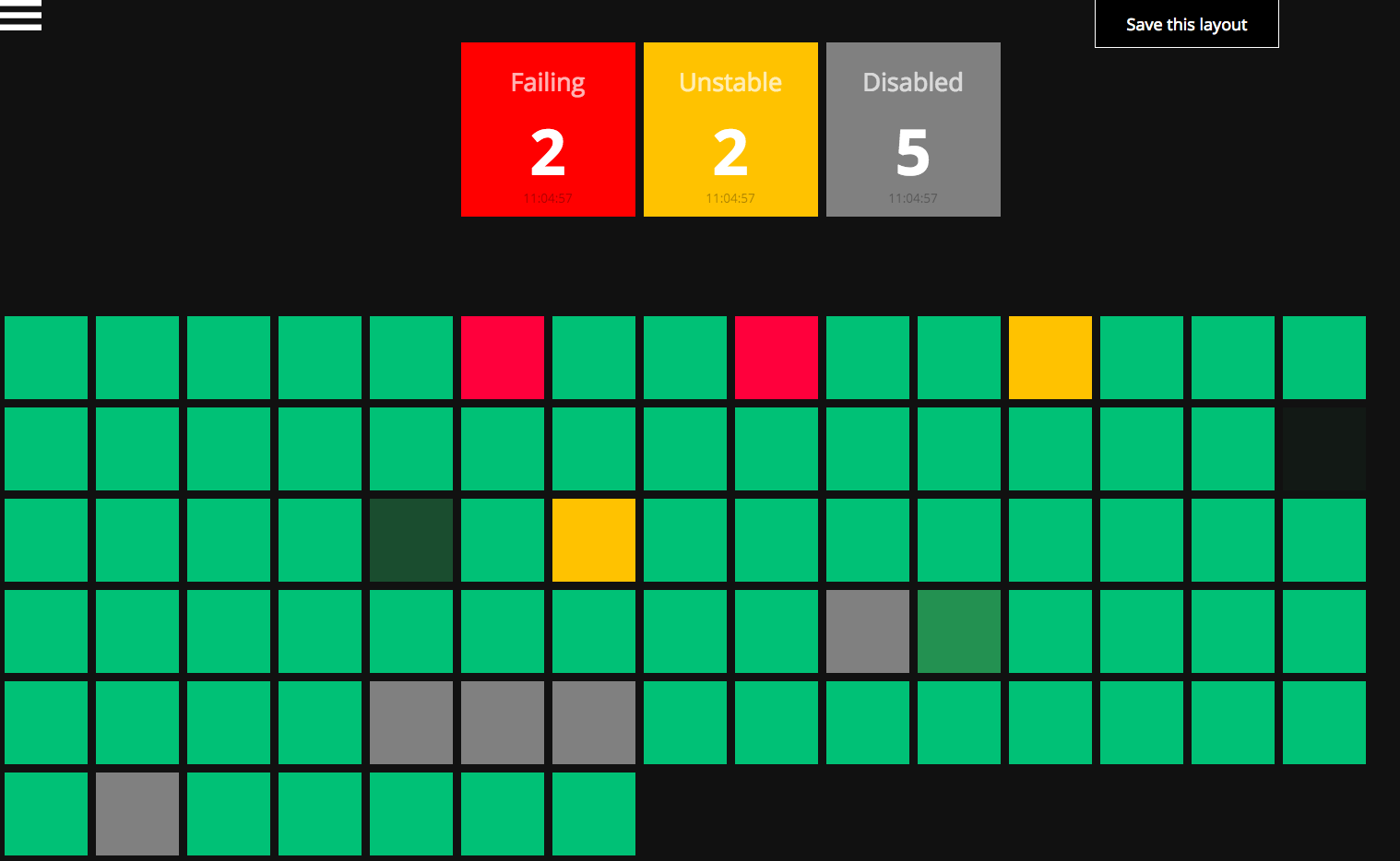
ZESHAN ANWAR: Eagle is a dashboard built for our Incubator team. With so many moving parts, it was important we had a summarized ‘birds-eye’ view of the team in one place. Eagle was initially meant to be an aggregation of all our Jenkin builds; a single view of all our jobs across our different Jenkins environments. However, it grew to also include JIRA and GitHub statistics. My other project was optimizing our UI tests by having them run concurrently. Our old UI tests were extremely slow, and by running them in parallel we drastically reduced test times.
BRENDON KELLEY: Testing Framework: This summer my project was to help build out a new testing framework for Curations. The current automation tests used for Curations is Saladhands. Before my internship, there wasn’t much if any automation tests for the submission/direct upload capability of Curations. I worked on creating tests and a CI environment for submission in a new testing framework called Intern. One of tests includes a language translation test using mongoDB as an endpoint to store the various languages’ text. Intern is a javascript based testing framework which will allow developers to contribute to writing tests since Curations is mostly javascript. I’ve also worked on updating and creating new console tests in this framework. The foundation built this summer in Intern will enable the ability to further contribute to the framework.
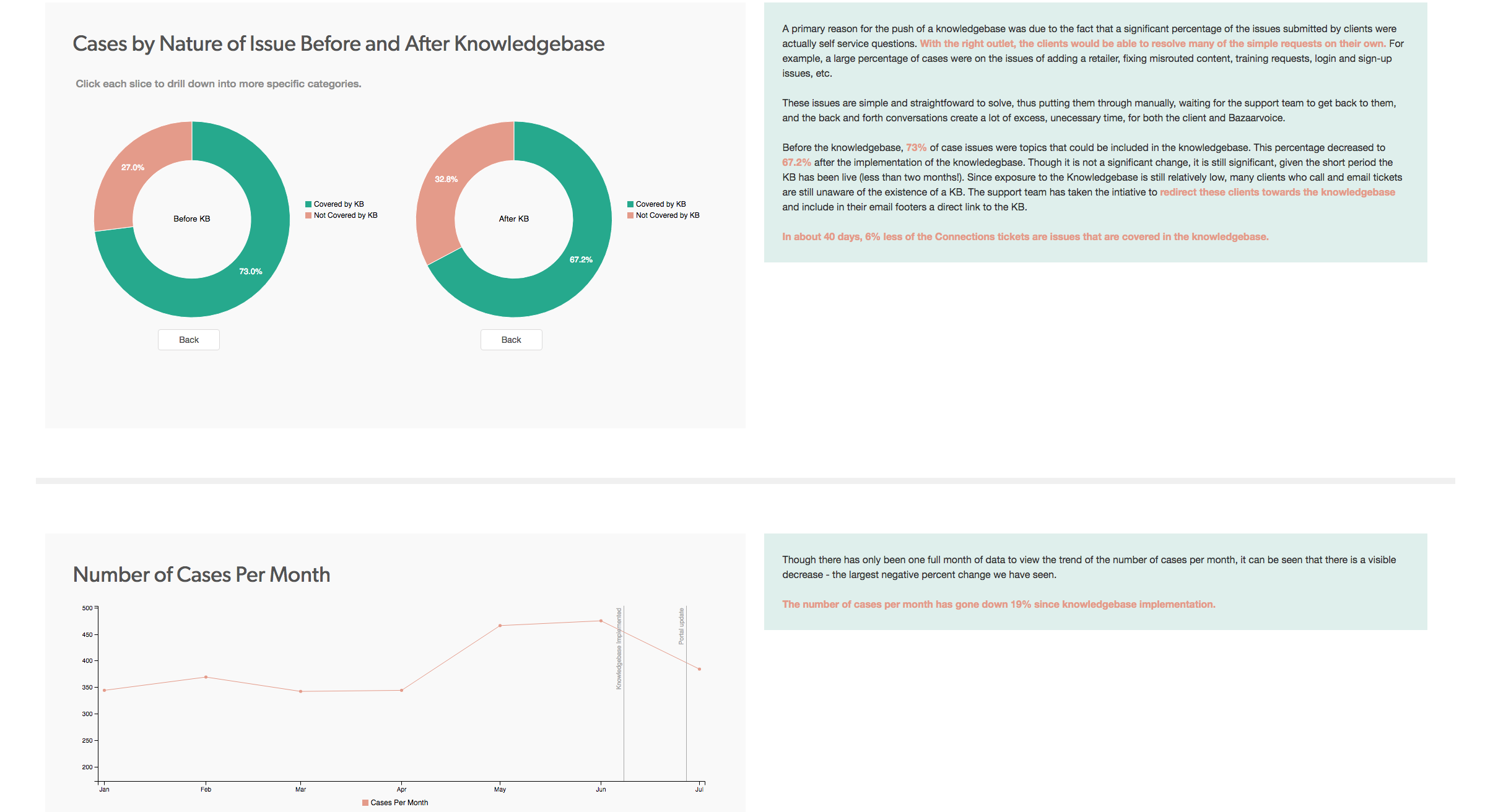
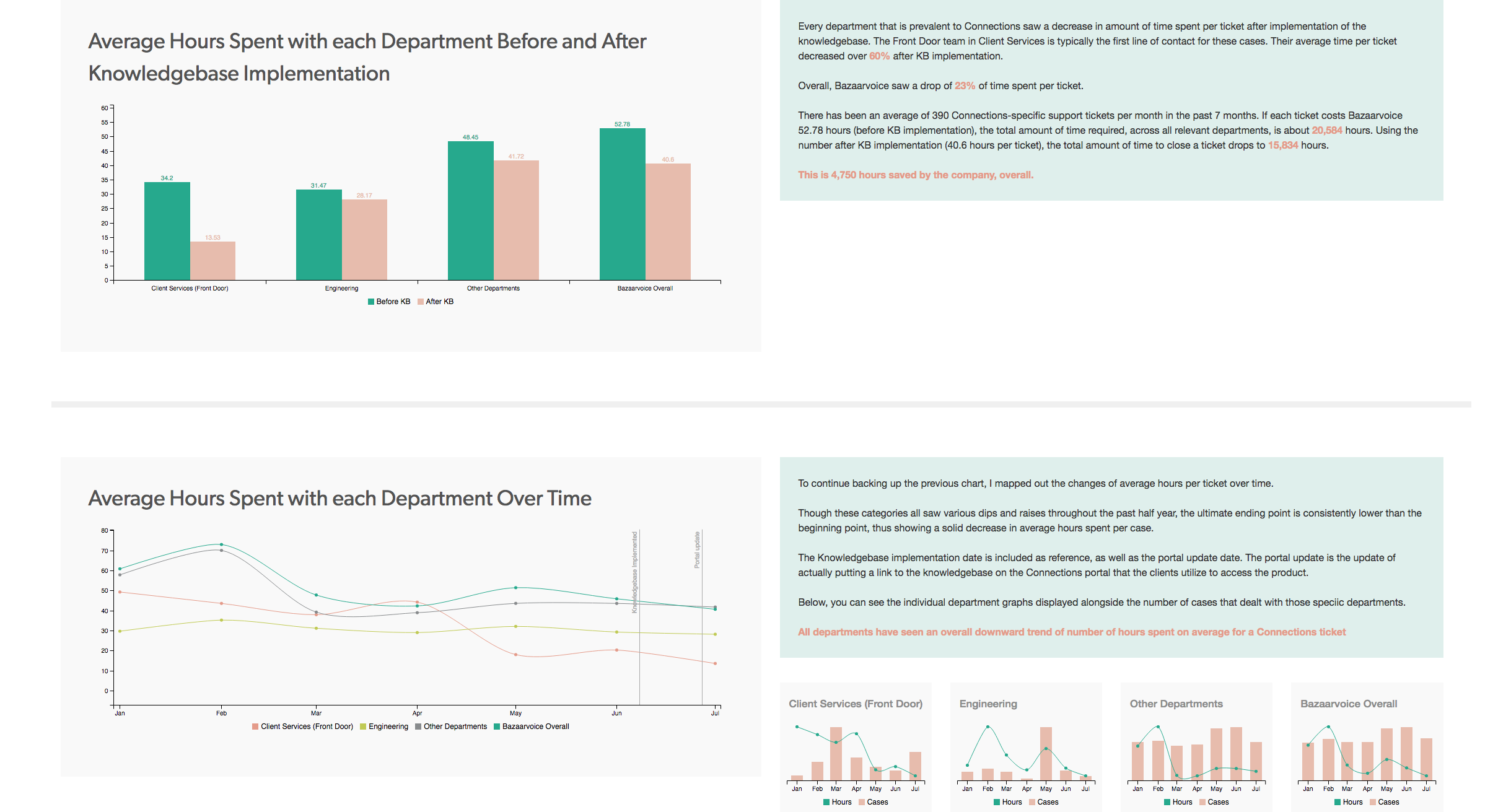
KRYSTINA DIAO: My main project for the summer was to analyze and report the effectiveness of the implementation of the new Connections Knowledgebase. Through Salesforce, I collected and analyzed the number of cases, time spent on each case, etc. After drawing my conclusions, I decided to present my findings via data visualization methods (JavaScript’s C3 and D3 libraries) and provide actionable insights on how this information can be leveraged. This information is valuable in that it can be used for future product KB decisions, as well as understanding how much time, manpower, and money is saved by having a KB.
MARKO SAVIC: Over the summer, I was a part of the SEO Team. I managed to create a tool on pagesManaged and keywordsManaged feed for every Spotlights client. Generated feeds will be consumed by SeoClarity tools on a daily basis. This helps in identifying search rank gains on the specified keywords and pages where Spotlights are present. The SeoClarity reporting will help in proving out Spotlights value and eventually lead to Spotlights renewal/upticks.Also, I created algorithm tweaks on the PINS (Post Interaction Notification System) Generator that take into account product activeness, product relevancy and review count, and use them to ask the user to write reviews on the most relevant products.
TREVOR NELLIGAN: Here is a description of my project: I worked on the Aperture Component library and many of the projects it supports. Aperture is build in React, and its purpose is to be used as an internal Bazaarvoice tool for constructing web pages. Using Aperture, anyone at Bazaarvoice can easily create a functional, intuitive, Bazaarvoice themed webpage, all with the building blocks Aperture provides.
Using the Aperture library, I helped the construction of numerous pages for the curations beta console. I personally built the interface for a new client-facing template builder, which will allow clients to create curations templates quickly and easily without having to go through an implementation engineer and a long process, as was the case previously. I also supplied custom Aperture components for several projects, like the content curation beta page.
RAMIE RAUFDEEN: The mixer is a component of our product recommendations engine which differentiates shoppers, and optimizes recommendations for them. This is primarily derived from their shopping behavior – in real time. Prior to the mixer, product recommendations were aggregated from multiple sources, using the same algorithm for every shopper. Shoppers are now categorized based off of a set of rules (using the shopper’s profile data), each of the rules map to a plan (which you can think of as an ‘algorithm’). A plan defines how recommendations should be mixed from each of the sources. For example, if source B has proven to have a higher conversion rate for ‘heavy-shoppers’, the plan for ‘heavy-shopper’ would give a higher weighting to source B. We can now target specific types of shoppers when it comes to product recommendations. This also sets the groundwork for a more granular machine learning implementation in the future.
We want to thank all the interns who spent time with us this summer and wish you the best back at school. We look forward to hearing about all the great things you all develop in the future.
If you are interested in an internship at Bazaarvoice, please contact kindall.heye@bazaarvoice.com.