
The holiday season brings a huge spike in traffic for many companies. While increased traffic is great for retail business, it also puts infrastructure reliability to the test. At times when every second of uptime is of elevated importance, how can engineering teams ensure zero downtime and performant applications? Here are some key strategies and considerations we employ at Bazaarvoice as we prepare our platform to handle over 16 Billion API calls during Cyber Week.

Key to approaching readiness for peak load events is defining the scope of testing. Identify which services need to be tested and be clear about success requirements. A common trade off will be choosing between reliability and cost. When making this choice, reliability is always the top priority. ‘Customer is Key’ is a key value at Bazaarvoice, and drives our decisions and behavior. Service Level Objectives (SLOs) drive clarity of reliability requirements through each of our services.
“Reliability is always the top priority“
When customer traffic is at its peak, reliability and uptime must take precedence over all other concerns. While cost efficiency is important, the customer experience is key during these critical traffic surges. Engineers should have the infrastructure resources they need to maintain stability and performance, even if it means higher costs in the short-term.
Thorough testing and validation well in advance is essential to surfacing any issues before the holidays. All critical customer-facing services undergo load and failover simulations to identify performance bottlenecks and points of failure. In a Serverless-first architecture, ensuring configuration like reserved concurrency and quota limits are sufficient for autoscaling requirements are valuable to validate. Often these simulations will uncover problems you have not previously encountered. For example, in this year’s preparations our load simulations uncovered scale limitations in our redis cache which required fixes prior to Black Friday.
“It’s not only about testing the ability to handle peak load”
It’s important to note readiness is not only about testing the ability to handle peak load. Disaster recovery plans are validated through simulated scenarios. Runbooks are verified as up-to-date, to ensure efficient incident response in the event something goes wrong. Verifying instrumentation and infrastructure that supports operability are tested, ensuring our tooling works when we need it most.
Similarly ensuring the appropriate tooling and processes are in place to address security concerns is another key concern. Preventing DDoS attacks which could easily overwhelm the system if not identified and mitigated, preventing impact of service availability.
Predicting the future
Observability through actionable monitoring, logging, and metrics provides the essential visibility to detect and isolate emerging problems early. It also provides the historical context and growth of traffic data over time, which can help forecast capacity needs and establish performance baselines that align with real production usage. In addition to quantitative measures, proactively reaching out to clients means we are in step with client needs about expected traffic helping align testing to actual usage patterns. This data is important to simulate real world traffic patterns based on what has gone before, and has enabled us to accurately predict Black Friday traffic trends. However it’s important our systems are architected to scale with demand, to handle unpredicted load if need be, key to this is observing and understanding how our systems behave in production.
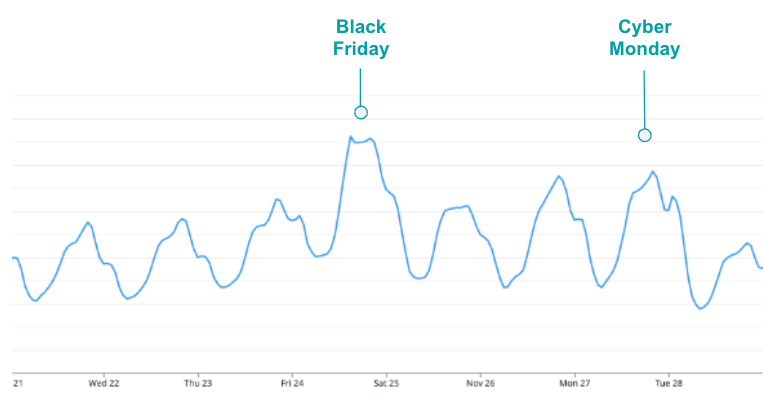
Traffic Trends
What did it look like this year? Consumer shopping patterns remained quite consistent on an elevated scale. Black Friday continues to be the largest shopping day of the year, and consumers continue to shop online in increasing numbers. During Cyber Week alone, Bazaarvoice handled over 16 Billion API calls.
Solving common problems once
While individual engineering teams own service readiness, having a coordinated effort ensures all critical dependencies are covered. Sharing forecasts, requirements, and learnings across teams enables better preparation. Testing surprises on dependent teams should be avoided through clear communication.
Automating performance testing, failover drills, and monitoring checks as part of regular release cycles or scheduled pipelines reduces the overhead of peak traffic preparation. Following site reliability principles and instilling always-ready operational practices makes services far more resilient year-round.
For example, we recently put in place a shared dev pattern for continuous performance testing. This involves a quick setup of k6 performance script, an example github action pipeline and observability configured to monitor performance over time. We also use an in-house Tech Radar to converge on common tooling so a greater number of teams can learn and stand on the shoulders of teams who have already tried and tested tooling in their context.
Other examples include, adding automation to performance tests to replay production requests for a given load profile makes tests easier to maintain, and reflect more accurately production behavior. Additionally, make use of automated fault injection tooling, chaos engineering and automated runbooks.

Adding automation and ensuring these practices are part of your everyday way of working are key to reducing the overhead of preparing for the holidays.
Consistent, continuous training conditions us to always be ready
Moving to an always-ready posture ensures our infrastructure is scalable, reliable and robust all year round. Implementing continuous performance testing using frequent baseline tests provides frequent feedback on performance from release to release. Automated operational readiness service checks ensure principles and expectations are in place for production services and are continuously checked. For example, automated checking of expected monitors, alerts, runbooks and incident escalation policy requirements.
At Bazaarvoice our engineering teams align on shared System Standards which gives technical direction and guidance to engineers on commonly solved problems, continuously evolving our systems and increasing our innovation velocity. To use a trail running analogy, System Standards define the preferred paths and combined with Tech Radar, provide recommendations to help you succeed. For example, what trail running shoes should I choose, what energy refuelling strategy should I use, how should I monitor performance. The same is true for building resilient reliable software, as teams solve these common problems, share the learnings for those teams which come after.
Looking Ahead
With a relentless focus on reliability, scalability, continuous testing, enhanced observability, and cross-team collaboration, engineering organizations can optimize performance and minimize downtime during critical traffic surges.
Don’t forget after the peak has passed and we have descended from the summit, analyze the data. What went well, what didn’t go well, and what opportunities are there to improve for the next peak.