
On the racetrack of building ML applications, traditional software development steps are often overtaken. Welcome to the world of MLOps, where unique challenges meet innovative solutions and consistency is king.
At Bazaarvoice, training pipelines serve as the backbone of our MLOps strategy. They underpin the reproducibility of our model builds. A glaring gap existed, however, in graduating experimental code to production.
Rather than continuing down piecemeal approaches, which often centered heavily on Jupyter notebooks, we determined a standard was needed to empower practitioners to experiment and ship machine learning models extremely fast while following our best practices.
(cover image generated with Midjourney)
Build vs. Buy

Fresh off the heels of our wins from unifying our machine learning (ML) model deployment strategy, we first needed to decide whether to build a custom in-house ML workflow orchestration platform or seek external solutions.
When deciding to “buy” (it is open source after all), selecting Flyte as our workflow management platform emerged as a clear choice. It saved invaluable development time and nudged our team closer to delivering a robust self-service infrastructure. Such an infrastructure allows our engineers to build, evaluate, register, and deploy models seamlessly. Rather than reinventing the wheel, Flyte equipped us with an efficient wheel to race ahead.
Before leaping with Flyte, we embarked on an extensive evaluation journey. Choosing the right workflow orchestration system wasn’t just about selecting a tool but also finding a platform to complement our vision and align with our strategic objectives. We knew the significance of this decision and wanted to ensure we had all the bases covered. Ultimately the final tooling options for consideration were Flyte, Metaflow, Kubeflow Pipelines, and Prefect.
To make an informed choice, we laid down a set of criteria:
Criteria for Evaluation
Must-Haves:
- Ease of Development: The tool should intuitively aid developers without steep learning curves.
- Deployment: Quick and hassle-free deployment mechanisms.
- Pipeline Customization: Flexibility to adjust pipelines as distinct project requirements arise.
- Visibility: Clear insights into processes for better debugging and understanding.
Good-to-Haves:
- AWS Integration: Seamless integration capabilities with AWS services.
- Metadata Retention: Efficient storage and retrieval of metadata.
- Startup Time: Speedy initialization to reduce latency.
- Caching: Optimal data caching for faster results.
Neutral, Yet Noteworthy:
- Security: Robust security measures ensuring data protection.
- User Administration: Features facilitating user management and access control.
- Cost: Affordability – offering a good balance between features and price.
Why Flyte Stood Out: Addressing Key Criteria
Diving deeper into our selection process, Flyte consistently addressed our top criteria, often surpassing the capabilities of other tools under consideration:
- Ease of Development: Pure Python | Task Decorators
- Python-native development experience
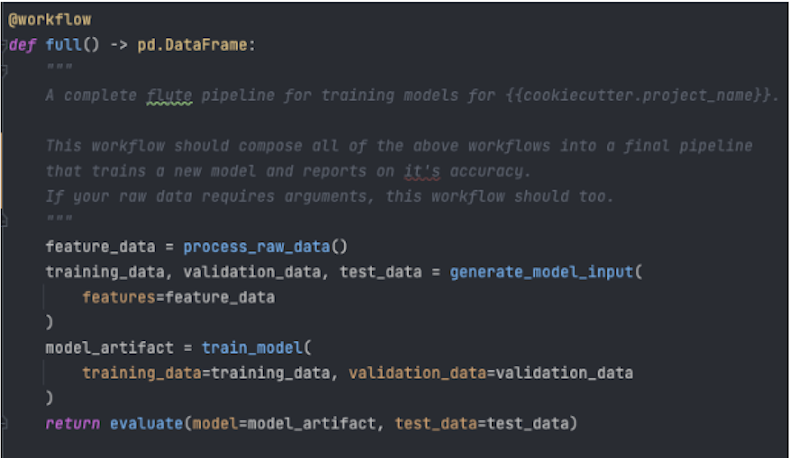
- Python-native development experience
- Pipeline Customization
- Easily customize any workflow and task by modifying the task decorator

- Easily customize any workflow and task by modifying the task decorator
- Deployment: Kubernetes Cluster
- Visibility
- Easily accessible container logs
- Flyte decks enable reporting visualizations
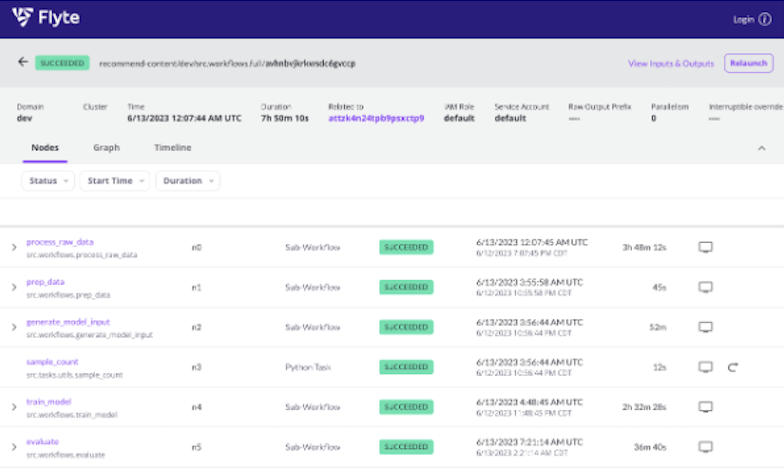
- Flyte’s native Kubernetes integration simplified the deployment process.
The Bazaarvoice customization

As with any platform, while Flyte brought many advantages, we needed a different plug-and-play solution for our unique needs. We anticipated the platform’s novelty within our organization. We wanted to reduce the learning curve as much as possible and allow our developers to transition smoothly without being overwhelmed.
To smooth the transition and expedite the development process, we’ve developed a cookiecutter template to serve as a launchpad for developers, providing a structured starting point that’s standardized and aligned with best practices for Flyte projects. This structure empowers developers to swiftly construct training pipelines.
The most relevant files provided by the template are:
Pipfile - Details project dependenciesDockerfile - Builds docker containerMakefile - Helper file to build, register, and execute projectsREADME.md - Details the projectsrc/tasks/Workflows.py (Follows the Kedro Standard for Data Layers)process_raw_data - workflow to extract, clean, and transform raw datagenerate_model_input - workflow to create train, test, and validation data setstrain_model - workflow to generate a serialized, trained machine learning modelgenerate_model_output - workflow to prevent train-serving skew by performing inference on the validation data set using the trained machine learning modelevaluate - workflow to evaluate the model on a desired set of performance metricsreporting - workflow to summarize and visualize model performancefull - complete Flyte pipeline to generate trained model
tests/ - Unit tests for your workflows and tasksrun - Simplifies running of workflows
In addition, a common challenge in developing pipelines is needing resources beyond what our local machines offer. Or, there might be tasks that require extended runtimes. Flyte does grant the capability to develop locally and run remotely. However, this involves a series of steps:
- Rebuild your custom docker image after each code modification.
- Assign a version tag to this new docker image and push it to ECR.
- Register this fresh workflow version with Flyte, updating the docker image.
- Instruct Flyte to execute that specific version of the workflow, parameterizing via the CLI.
To circumvent these challenges and expedite the development process, we designed the template’s Makefile and run script to abstract the series of steps above into a single command!
./run —remote src/workflows.py full
The Makefile uses a couple helper targets, but overall provides the following commands:
info - Prints info about this projectinit - Sets up project in flyte and creates an ECR repobuild - Builds the docker imagepush - Pushes the docker image to ECRpackage - Creates the flyte packageregister - Registers version with flyteruncmd - Generates run command for both local and remotetest - Runs any tests for the codecode_style - Applies black formatting & flake8
Key Triumphs
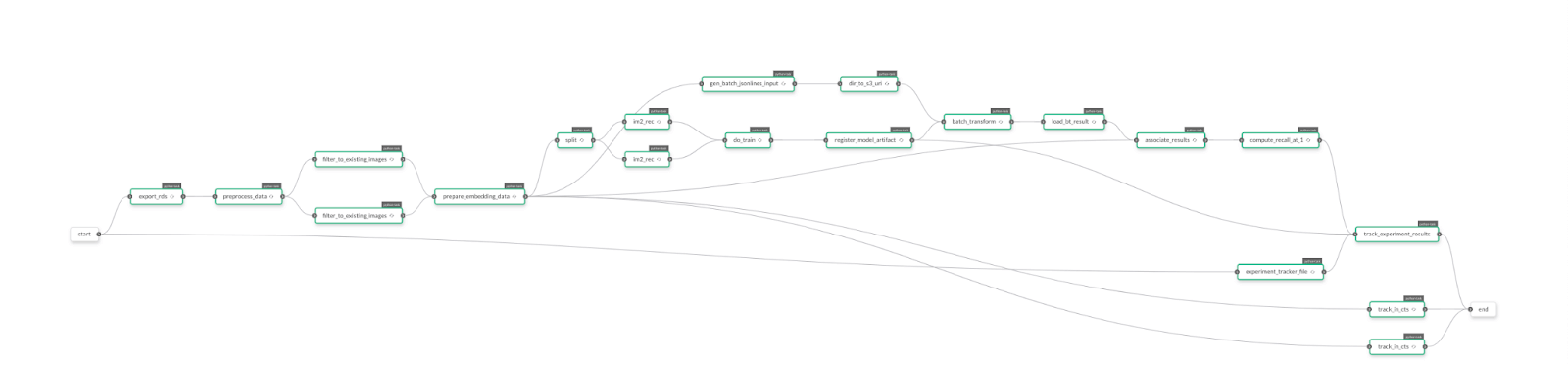
With Flyte as an integral component of our machine learning platform, we’ve achieved unmatched momentum in ML development. It enables swift experimentation and deployment of our models, ensuring we always adhere to best practices. Beyond aligning with fundamental MLOps principles, our customizations ensure Flyte perfectly meets our specific needs, guaranteeing the consistency and reliability of our ML models.
Closing Thoughts
Just as racers feel exhilaration crossing the finish line, our team feels an immense sense of achievement seeing our machine learning endeavors zoom with Flyte. As we gaze ahead, we’re optimistic, ready to embrace the new challenges and milestones that await. 🏎️
If you are drawn to this type of work, check out our job openings.